INDEX
PostgreSQL의 INDEX(인덱스)는 데이터베이스의 성능을 향상시키기 위한 중요한 구조로, 테이블에 저장된 데이터를 효율적으로 검색할 수 있도록 돕습니다. 인덱스를 활용하면 쿼리의 검색 속도를 크게 개선할 수 있지만, 인덱스를 잘못 설계하거나 남용하면 오히려 성능에 부정적인 영향을 미칠 수 있습니다.
1. INDEX란?
- INDEX는 데이터베이스 테이블의 특정 열(Column)에 대해 생성되는 별도의 데이터 구조입니다.
- 인덱스를 사용하면 데이터를 검색할 때 테이블의 모든 행을 확인하지 않아도 되므로, 검색 속도가 빨라집니다.
- 예: 책의 목차처럼, 데이터가 저장된 위치를 빠르게 찾아갈 수 있도록 하는 역할.
2. INDEX의 동작 원리
- 테이블 스캔:
- 인덱스가 없는 경우, PostgreSQL은 테이블의 모든 행을 확인(Sequential Scan)하여 조건에 맞는 데이터를 찾습니다.
- 이는 데이터가 많을수록 시간이 많이 걸립니다.
- 인덱스 검색:
- 인덱스를 사용하면, 특정 키를 기반으로 데이터를 빠르게 검색할 수 있습니다.
- PostgreSQL은 쿼리 플래너(Query Planner)를 통해 인덱스를 사용할지 여부를 결정합니다.
3. INDEX의 종류
PostgreSQL은 다양한 유형의 인덱스를 지원하며, 사용 사례에 따라 선택할 수 있습니다.
(1) B-Tree Index (기본 인덱스)
- 설명:
- 기본 인덱스 유형으로, 대부분의 경우 기본값으로 사용됩니다.
- 정렬된 데이터 검색에 적합합니다.
- 사용 예:
- 등호(=), 비교 연산자(>, <), 범위 조건(BETWEEN) 등.
- 생성 예:
CREATE INDEX idx_users_name ON users(name);
(2) Hash Index
- 설명:
- 해시 알고리즘을 사용하여 데이터를 인덱싱.
- 정확한 값 일치(Equality) 검색에 적합.
- 사용 예:
- 등호(=) 조건에서만 사용 가능.
- 생성 예:
CREATE INDEX idx_users_email ON users USING hash(email);
(3) GIN (Generalized Inverted Index)
- 설명:
- 배열, JSONB, 텍스트 검색 등에 사용.
- 문서 검색 또는 다중 키워드 검색에 적합.
- 사용 예:
- 텍스트에서 특정 단어를 검색.
- 생성 예:
CREATE INDEX idx_posts_content ON posts USING gin(to_tsvector('english', content));
(4) GiST (Generalized Search Tree)
- 설명:
- 범위, 기하학적 데이터 검색에 적합.
- 복잡한 조건에 대해 효율적으로 검색 가능.
- 사용 예:
- 공간 검색, 근접 검색(Nearest Neighbor).
- 생성 예:
CREATE INDEX idx_locations_geom ON locations USING gist(geom);
(5) BRIN (Block Range Index)
- 설명:
- 대량의 데이터를 저장한 테이블에서 특정 범위 검색에 효율적.
- 데이터를 저장된 순서로 분석.
- 사용 예:
- 시간대별 데이터 검색.
- 생성 예:
CREATE INDEX idx_logs_date ON logs USING brin(log_date);
4. INDEX 생성 및 관리
(1) 인덱스 생성
CREATE INDEX idx_table_column ON table_name(column_name);
(2) 복합 인덱스
- 여러 열을 기반으로 검색할 경우, 복합 인덱스를 생성할 수 있습니다.
CREATE INDEX idx_table_columns ON table_name(column1, column2);
(3) UNIQUE 인덱스
- 중복을 허용하지 않는 인덱스를 생성합니다.
CREATE UNIQUE INDEX idx_unique_email ON users(email);
(4) 인덱스 삭제
DROP INDEX idx_table_column;
(5) 자동 인덱스
- Primary Key 또는 Unique Constraint를 정의하면 PostgreSQL이 자동으로 인덱스를 생성합니다.
5. INDEX의 장단점
장점
- 검색 성능 향상:
- 데이터를 빠르게 검색할 수 있음.
- 정렬 속도 개선:
- ORDER BY 쿼리에서 성능이 개선됨.
- 제약 조건 지원:
- UNIQUE, PRIMARY KEY 등의 제약 조건 구현에 사용.
단점
- 쓰기 작업 성능 저하:
- INSERT, UPDATE, DELETE 작업 시 인덱스를 업데이트해야 하므로 성능이 저하될 수 있음.
- 추가적인 저장 공간 필요:
- 인덱스는 디스크 공간을 차지.
- 불필요한 인덱스의 성능 저하:
- 과도한 인덱스는 쿼리 플래너를 혼란스럽게 하여 성능에 부정적 영향을 미칠 수 있음.
6. INDEX 사용 시 주의사항
(1) 적절한 인덱스 선택
- 인덱스는 자주 사용되는 쿼리 조건에만 적용하는 것이 좋습니다.
- 드물게 사용되는 열에 인덱스를 추가하면 오히려 성능이 저하될 수 있습니다.
(2) VACUUM 및 ANALYZE
- 인덱스의 최적화와 유지 관리를 위해 주기적으로
VACUUM및ANALYZE를 실행해야 합니다.VACUUM ANALYZE;
(3) EXPLAIN을 통한 쿼리 최적화
EXPLAIN또는EXPLAIN ANALYZE를 사용하여 쿼리에서 인덱스가 제대로 사용되는지 확인합니다.EXPLAIN SELECT * FROM users WHERE name = 'Alice';
7. INDEX 사용 예시
기본 테이블 생성
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
인덱스 생성
CREATE INDEX idx_users_name ON users(name);
인덱스 활용 쿼리
SELECT * FROM users WHERE name = 'Alice';
EXPLAIN으로 인덱스 확인
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
출력 예:
Index Scan using idx_users_name on users (cost=0.28..8.52 rows=1 width=64)
- “Index Scan”은 인덱스를 사용했음을 나타냅니다.
요약
- INDEX는 PostgreSQL에서 데이터 검색 성능을 최적화하는 데 중요한 역할을 합니다.
- 여러 유형의 인덱스(B-Tree, Hash, GIN 등)가 있으며, 데이터와 쿼리 유형에 따라 적합한 인덱스를 선택해야 합니다.
- 주의: 모든 열에 인덱스를 생성하면 오히려 성능이 저하될 수 있으므로, 필요에 따라 선택적으로 인덱스를 사용해야 합니다.
EXPLAIN, EXPLAIN ANALYZE
PostgreSQL의 EXPLAIN과 EXPLAIN ANALYZE는 데이터베이스 쿼리의 실행 계획을 분석하고 최적화할 때 사용하는 도구입니다. 이 두 가지는 쿼리가 데이터를 어떻게 처리하는지, 테이블을 어떻게 스캔하고 인덱스를 사용하는지, 쿼리의 효율성이 어떤지에 대한 정보를 제공합니다.
1. EXPLAIN
목적:
- 쿼리를 실제로 실행하지 않고, PostgreSQL이 해당 쿼리를 처리하기 위해 사용하는 실행 계획을 보여줍니다.
기본 문법:
EXPLAIN [쿼리];
주요 정보:
- 쿼리 계획(Query Plan):
- 쿼리에서 어떤 작업이 이루어지는지 단계별로 표시합니다.
- 각 단계에서 어떤 연산(예:
Seq Scan,Index Scan,Nested Loop등)이 수행되는지 나타냅니다.
- 예상 비용(Cost):
cost=...는 PostgreSQL의 내부 추정값으로, 쿼리 실행의 상대적 비용을 보여줍니다.- 시작 비용(start-up cost)과 총 비용(total cost)을 제공합니다.
- 예상 행 수(Rows):
- 각 단계에서 처리할 것으로 예상되는 데이터 행(row)의 수를 나타냅니다.
예제:
EXPLAIN SELECT * FROM users WHERE name = 'Alice';
출력 예:
Seq Scan on users (cost=0.00..35.50 rows=1 width=64)
Filter: (name = 'Alice')
Seq Scan: 테이블의 모든 행을 순차적으로 스캔.cost=0.00..35.50:0.00: 시작 비용.35.50: 전체 쿼리를 실행하는 데 필요한 예상 비용.
rows=1: 쿼리가 반환할 것으로 예상되는 행의 수.width=64: 각 행의 평균 바이트 크기(데이터 크기).
2. EXPLAIN ANALYZE
목적:
- 쿼리를 실제로 실행하여, 실행 계획과 함께 실제 실행 시간 및 쿼리 성능 정보를 제공합니다.
기본 문법:
EXPLAIN ANALYZE [쿼리];
주요 정보:
- 실제 실행 시간(Actual Time):
- 쿼리의 각 단계가 실행되는 데 걸린 실제 시간(밀리초 단위)을 표시.
- 실제 처리된 행 수:
- 각 단계에서 실제로 처리된 데이터 행의 수를 나타냅니다.
- 쿼리의 전체 실행 시간:
- 쿼리가 완료되기까지 걸린 총 시간을 표시.
예제:
EXPLAIN ANALYZE SELECT * FROM users WHERE name = 'Alice';
출력 예:
Seq Scan on users (cost=0.00..35.50 rows=1 width=64) (actual time=0.030..0.045 rows=1 loops=1)
Filter: (name = 'Alice')
Rows Removed by Filter: 99
Planning Time: 0.200 ms
Execution Time: 0.100 ms
actual time=0.030..0.045:- 해당 작업이 시작되고 완료되기까지 걸린 시간.
rows=1:- 실제로 반환된 행의 수.
Rows Removed by Filter: 99:- 조건에 맞지 않아 필터링된 행의 수.
Planning Time: 0.200 ms:- 쿼리 계획을 생성하는 데 걸린 시간.
Execution Time: 0.100 ms:- 전체 쿼리를 실행하는 데 걸린 총 시간.
3. EXPLAIN과 EXPLAIN ANALYZE 비교
| 특징 | EXPLAIN | EXPLAIN ANALYZE |
|---|---|---|
| 실제 쿼리 실행 | 실행하지 않음 | 실행함 |
| 출력 정보 | 실행 계획 및 추정 비용 정보 | 실행 계획, 실제 실행 시간 및 실제 처리된 데이터 |
| 사용 목적 | 실행 계획을 확인하고, 예상 성능 문제 분석 | 실제 쿼리 성능 확인 및 최적화 |
| 성능 테스트 가능성 | 데이터에 영향을 주지 않음 | 데이터에 영향을 줄 수 있음 (특히 DML 쿼리) |
4. 출력 요소 설명
- Operation Type:
- PostgreSQL이 쿼리를 처리하기 위해 사용하는 작업 유형.
- 주요 연산:
Seq Scan: 테이블의 모든 행을 순차적으로 읽음.Index Scan: 인덱스를 사용해 특정 행만 검색.Nested Loop: 두 테이블의 행을 조합.Hash Join: 해시 테이블을 사용해 두 테이블을 조합.
- Cost:
cost=0.00..35.50:- 시작 비용(0.00): 해당 작업을 시작하는 데 필요한 비용.
- 총 비용(35.50): 작업이 완료되기까지의 예상 총 비용.
- Rows:
- 해당 작업에서 처리될 것으로 예상되는 데이터 행의 수.
- Actual Time:
- 각 작업이 실행되는 데 걸린 실제 시간(밀리초).
- Loops:
- 해당 작업이 반복 실행된 횟수.
5. 활용 사례
(1) 성능 분석
- 특정 쿼리가 느리게 실행된다면,
EXPLAIN또는EXPLAIN ANALYZE로 실행 계획을 분석하여 병목 지점을 확인합니다. - 예: 인덱스가 없어서
Seq Scan이 발생하면, 인덱스를 추가하여 최적화.
(2) 인덱스 최적화
- 쿼리가 인덱스를 제대로 사용하고 있는지 확인합니다.
- 예:
CREATE INDEX idx_users_name ON users(name);
(3) 조인 성능 분석
- 두 테이블 간의 조인에서 적절한 방법(
Nested Loop,Hash Join,Merge Join)이 사용되고 있는지 확인.
6. 주의사항
EXPLAIN ANALYZE는 실제 쿼리 실행:- 쿼리가 데이터를 수정하는 경우(DML: INSERT, UPDATE, DELETE), 테스트 데이터베이스에서 실행해야 합니다.
- 실제 데이터에 영향을 줄 수 있습니다.
- 비용은 상대적인 값:
cost는 PostgreSQL의 내부 계산 기준으로, 절대적인 실행 시간과는 다를 수 있습니다.
7. 요약
EXPLAIN: 쿼리를 실행하지 않고, PostgreSQL의 실행 계획과 예상 비용 정보를 제공합니다.EXPLAIN ANALYZE: 쿼리를 실행하여 실제 실행 시간 및 데이터 처리 정보를 포함한 실행 계획을 제공합니다.- 이를 활용하면 병목 현상 파악, 인덱스 최적화, 쿼리 성능 개선에 도움을 줄 수 있습니다.
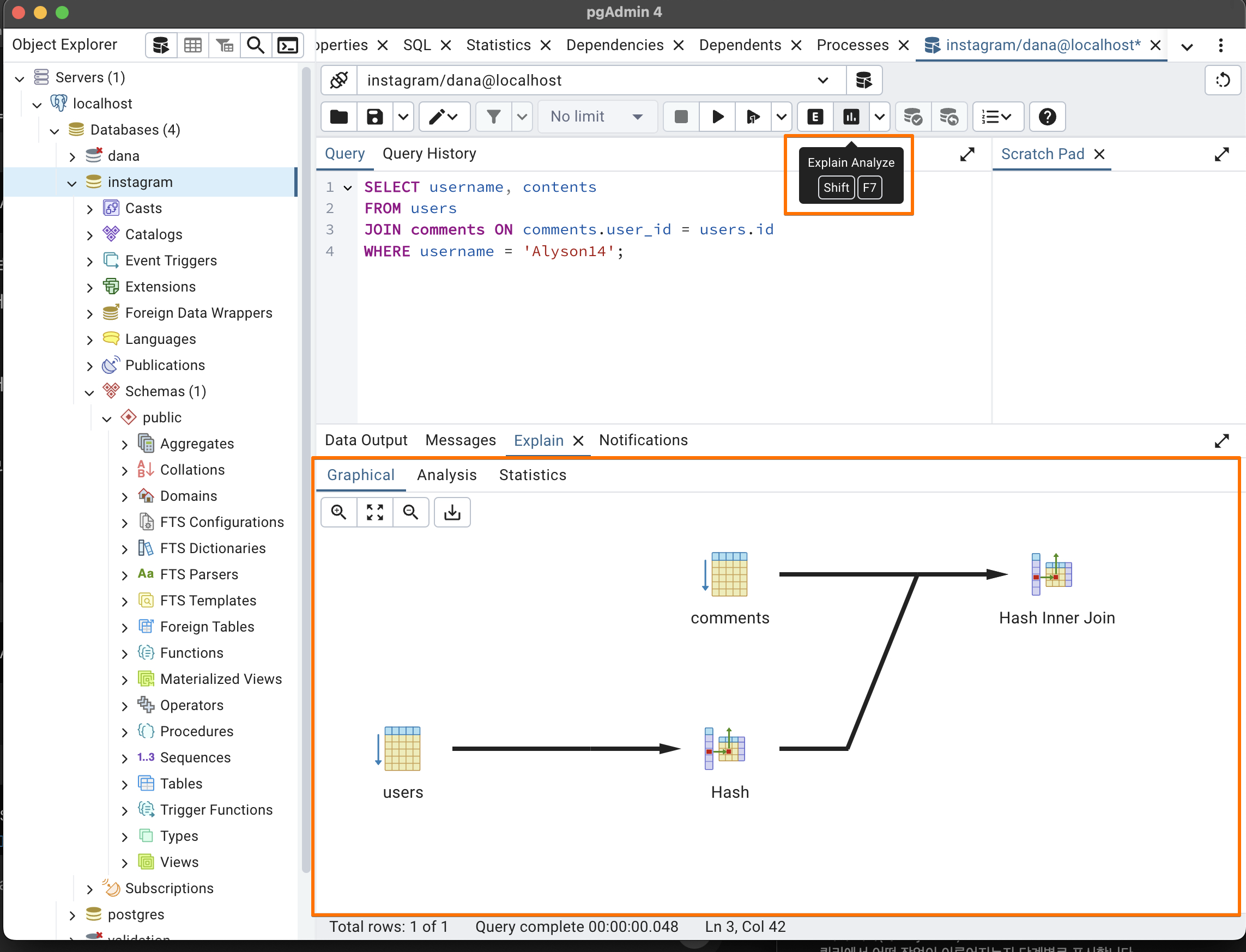
- pgAdmin에서 GUI로도 볼 수 있음
RECURSIVE CTE
PostgreSQL에서 RECURSIVE는 공통 테이블 표현식(CTE, Common Table Expression)과 함께 사용되어 재귀 쿼리를 작성할 때 사용됩니다. 이는 계층적 데이터 구조를 처리하거나, 반복적으로 데이터를 생성하고 변환하는 데 유용합니다.
1. RECURSIVE의 개념
- RECURSIVE CTE는 자기 참조를 통해 반복적으로 데이터를 생성하거나 쿼리를 수행하는 기능입니다.
- 계층적 데이터(예: 조직 구조, 디렉토리 구조, 그래프 탐색)를 처리하는 데 주로 사용됩니다.
- RECURSIVE 키워드는
WITH문과 함께 사용됩니다.
2. RECURSIVE CTE의 동작 방식
RECURSIVE CTE는 두 단계로 구성됩니다:
- Anchor Query:
- 재귀의 시작점입니다. 초기 데이터를 정의합니다.
- Recursive Query:
- Anchor Query의 결과를 반복적으로 참조하여 추가 데이터를 생성합니다.
- 이 쿼리는 자기 자신을 참조하여 동작합니다.
종료 조건:
- 재귀 쿼리가 더 이상 결과를 생성하지 않을 때 종료됩니다.
3. 문법
WITH RECURSIVE cte_name AS (
-- Anchor Query
initial_query
UNION ALL
-- Recursive Query
recursive_query
)
SELECT * FROM cte_name;
WITH RECURSIVE: CTE가 재귀적으로 동작함을 지정.initial_query: 재귀를 시작할 첫 데이터를 생성.UNION ALL: Anchor Query와 Recursive Query 결과를 결합. (UNION도 가능하지만, 중복 제거로 인해 성능 저하 가능성 있음.)recursive_query: 이전 결과를 기반으로 추가 데이터를 생성.
4. 예제
1) 계층적 데이터: 조직 구조
employees 테이블이 아래와 같이 있다고 가정합니다:
| employee_id | name | manager_id |
|---|---|---|
| 1 | Alice | NULL |
| 2 | Bob | 1 |
| 3 | Charlie | 1 |
| 4 | Dave | 2 |
| 5 | Eve | 3 |
이 테이블은 직원과 관리자 간의 계층 구조를 나타냅니다.
목표: Alice를 기준으로 모든 직원의 계층 구조를 조회.
쿼리:
WITH RECURSIVE employee_hierarchy AS (
-- Anchor Query: Alice부터 시작
SELECT employee_id, name, manager_id, 1 AS level
FROM employees
WHERE name = 'Alice'
UNION ALL
-- Recursive Query: 이전 결과에서 매니저가 직원인 행을 찾음
SELECT e.employee_id, e.name, e.manager_id, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.employee_id
)
SELECT * FROM employee_hierarchy;
결과:
| employee_id | name | manager_id | level |
|————-|———-|————|——-|
| 1 | Alice | NULL | 1 |
| 2 | Bob | 1 | 2 |
| 3 | Charlie | 1 | 2 |
| 4 | Dave | 2 | 3 |
| 5 | Eve | 3 | 3 |
2) 그래프 탐색: 경로 찾기
graph 테이블이 아래와 같이 있다고 가정합니다:
| start | end |
|---|---|
| A | B |
| A | C |
| B | D |
| C | D |
| D | E |
목표: A에서 E까지의 모든 경로를 찾기.
쿼리:
WITH RECURSIVE paths AS (
-- Anchor Query: 시작점 A
SELECT start, end, start || ' -> ' || end AS path
FROM graph
WHERE start = 'A'
UNION ALL
-- Recursive Query: 이전 끝점(end)을 새로운 시작점(start)으로 확장
SELECT p.start, g.end, p.path || ' -> ' || g.end
FROM paths p
JOIN graph g ON p.end = g.start
)
SELECT * FROM paths WHERE end = 'E';
결과:
| start | end | path |
|——-|——|———————|
| A | E | A -> B -> D -> E |
| A | E | A -> C -> D -> E |
5. RECURSIVE 사용 시 주의점
- 종료 조건 확인:
- 잘못된 종료 조건이나 무한 재귀가 발생할 수 있으므로, 쿼리가 언제 종료되는지 확실히 설계해야 합니다.
UNION ALLvsUNION:UNION ALL: 중복을 허용하며 성능이 더 좋음.UNION: 중복 제거로 인해 성능이 저하될 수 있음.
- 최대 재귀 깊이 설정:
- PostgreSQL은 기본적으로 최대 재귀 깊이를 50으로 제한합니다.
- 더 깊은 재귀가 필요한 경우 설정을 변경할 수 있습니다:
SET max_recursive_depth = 100;
- 성능 고려:
- 재귀 쿼리는 비용이 높을 수 있으므로, 필요한 최소 데이터만 처리하도록 설계해야 합니다.
6. 사용 사례
- 계층적 데이터 탐색:
- 조직도, 카테고리 트리, 디렉토리 구조.
- 그래프 탐색:
- 경로 찾기, 네트워크 연결 분석.
- 반복적 계산:
- 피보나치 수열, 반복적인 데이터 집계.
- 데이터 생성:
- 일정 범위의 데이터 생성 (예: 날짜 생성).
7. 간단한 데이터 생성 예제
목표: 1부터 10까지 숫자를 생성.
WITH RECURSIVE generate_numbers AS (
SELECT 1 AS num -- Anchor Query
UNION ALL
SELECT num + 1 -- Recursive Query
FROM generate_numbers
WHERE num < 10 -- 종료 조건
)
SELECT * FROM generate_numbers;
결과:
| num |
|—–|
| 1 |
| 2 |
| 3 |
| … |
| 10 |
요약
- RECURSIVE는 CTE와 함께 재귀적으로 데이터를 처리하거나 생성할 때 사용됩니다.
- 두 단계(Anchor Query와 Recursive Query)로 구성되며, 종료 조건을 잘 설계해야 합니다.
- PostgreSQL에서 계층적 데이터와 그래프 탐색 같은 복잡한 데이터 구조를 처리하는 데 유용합니다.
VIEW
VIEW는 PostgreSQL에서 테이블처럼 작동하는 가상의 데이터 집합입니다. 쿼리 결과를 저장하지 않고 동적으로 생성되는 테이블 형태의 객체로, 데이터베이스 사용자에게 특정 데이터를 제공하거나, 복잡한 쿼리를 단순화하는 데 유용합니다.
1. VIEW란?
- VIEW는 데이터베이스에서 가상의 테이블로 작동합니다.
- 실제 데이터를 저장하지 않고, 저장된 쿼리(SELECT 문)를 통해 동적으로 데이터를 생성합니다.
- VIEW를 사용하면 원본 데이터에 영향을 주지 않고, 데이터를 읽거나 조작할 수 있습니다.
2. VIEW의 특징
- 가상 테이블:
- VIEW는 데이터 자체를 저장하지 않으며, 정의된 SELECT 문이 실행될 때 동적으로 데이터를 가져옵니다.
- 데이터 추상화:
- 사용자에게 데이터의 특정 부분만 노출하거나, 복잡한 데이터 구조를 숨길 수 있습니다.
- 재사용 가능:
- 자주 사용하는 복잡한 쿼리를 VIEW로 정의하여, 간단하게 호출할 수 있습니다.
- 읽기 및 쓰기:
- 기본적으로 VIEW는 읽기 전용이지만, 조건에 따라 데이터를 삽입하거나 업데이트할 수도 있습니다.
3. VIEW 생성 및 삭제
VIEW 생성
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
예:
CREATE VIEW active_users AS
SELECT user_id, username, email
FROM users
WHERE status = 'active';
active_usersVIEW는users테이블에서 상태가 ‘active’인 사용자만 포함합니다.
VIEW 조회
VIEW는 테이블처럼 사용할 수 있습니다:
SELECT * FROM active_users;
VIEW 삭제
VIEW를 삭제하려면 다음 명령을 사용합니다:
DROP VIEW view_name;
예:
DROP VIEW active_users;
4. VIEW의 장점
- 데이터 추상화:
- 사용자는 VIEW를 통해 데이터의 특정 부분만 보거나, 복잡한 테이블 구조를 몰라도 데이터를 쉽게 조회할 수 있습니다.
- 예: 민감한 정보를 제외한 사용자 데이터 제공.
- 복잡한 쿼리 단순화:
- 복잡한 JOIN이나 필터 조건을 포함한 쿼리를 VIEW로 정의해 간단하게 사용할 수 있습니다.
- 예: 여러 테이블을 조인하여 결과를 반환하는 쿼리를 단일 VIEW로 만듦.
- 보안:
- VIEW를 통해 특정 데이터에만 접근 권한을 부여할 수 있습니다.
- 예: 원본 테이블의 민감한 정보를 숨기고, VIEW를 통해 제한된 데이터를 제공.
- 유지 보수:
- 자주 사용하는 쿼리를 VIEW로 정의하면, 쿼리를 변경할 때 한 곳만 수정하면 됩니다.
5. VIEW의 단점
- 성능 문제:
- VIEW는 동적으로 데이터를 생성하므로, 대규모 데이터에 대해 사용하면 성능이 저하될 수 있습니다.
- 복잡한 VIEW를 중첩 사용하거나, 여러 테이블을 조인하면 성능이 크게 저하될 수 있습니다.
- 읽기/쓰기 제한:
- 대부분의 VIEW는 읽기 전용입니다. 데이터를 수정하려면 추가적인 조건을 충족해야 합니다(예: 단순한 SELECT 문이어야 함).
- 데이터 최신성:
- VIEW는 항상 최신 데이터를 보여주지만, 이는 원본 데이터에 의존하므로 원본 데이터가 변경되면 VIEW 결과도 바뀝니다. 따라서 캐싱이 필요할 경우, 성능이 저하될 수 있습니다.
6. VIEW의 활용 예
(1) 데이터 추상화
사용자 정보에서 민감한 데이터를 숨기고 공개 가능한 데이터만 제공:
CREATE VIEW public_users AS
SELECT user_id, username, email
FROM users
WHERE is_public = TRUE;
(2) 복잡한 쿼리 단순화
주문 정보와 사용자 정보를 JOIN하여 자주 사용되는 결과를 VIEW로 정의:
CREATE VIEW user_orders AS
SELECT u.username, o.order_id, o.total_amount
FROM users u
JOIN orders o ON u.user_id = o.user_id;
사용:
SELECT * FROM user_orders WHERE total_amount > 100;
7. MATERIALIZED VIEW
PostgreSQL에서는 MATERIALIZED VIEW(물리적 뷰)도 지원합니다. 이는 일반 VIEW와 달리 결과를 디스크에 저장하므로, 성능이 중요한 작업에 유용합니다.
특징:
- 결과를 저장:
- 일반 VIEW는 동적으로 데이터를 가져오지만, MATERIALIZED VIEW는 쿼리 결과를 물리적으로 저장합니다.
- 성능 최적화:
- 복잡한 쿼리를 자주 실행해야 하는 경우, 성능을 크게 개선할 수 있습니다.
- 데이터 갱신 필요:
- 원본 데이터가 변경되면, MATERIALIZED VIEW를 수동으로 갱신해야 합니다.
MATERIALIZED VIEW 생성:
CREATE MATERIALIZED VIEW mat_view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
MATERIALIZED VIEW 갱신:
REFRESH MATERIALIZED VIEW mat_view_name;
8. VIEW와 MATERIALIZED VIEW 비교
| 특징 | VIEW | MATERIALIZED VIEW |
|---|---|---|
| 데이터 저장 여부 | 저장하지 않음 (동적 생성) | 디스크에 저장 |
| 최신 데이터 제공 여부 | 항상 최신 데이터 | 갱신 시 최신 데이터 제공 |
| 성능 | 대규모 데이터에 대해 느릴 수 있음 | 복잡한 쿼리에 대해 성능이 더 나음 |
| 갱신 필요 여부 | 필요 없음 | 수동 갱신 필요 |
9. 요약
- VIEW는 데이터를 저장하지 않는 가상의 테이블로, 데이터 추상화, 복잡한 쿼리 단순화, 보안 등을 제공.
- 읽기 전용이 기본이지만, 조건에 따라 데이터를 수정할 수도 있음.
- 성능이 중요한 경우, MATERIALIZED VIEW를 사용하여 결과를 캐싱하고 필요 시 갱신 가능.
 Schema Design
Schema Design