Transaction
Transaction이란?
Transaction(트랜잭션)은 데이터베이스에서 하나의 논리적 작업 단위를 말하며, 일련의 작업이 모두 성공하거나 모두 실패해야 하는 것을 보장합니다. PostgreSQL에서 트랜잭션은 데이터 무결성과 일관성을 유지하기 위해 사용됩니다.
트랜잭션의 주요 특징 (ACID)
- Atomicity (원자성):
- 트랜잭션 내의 모든 작업이 완료되거나 모두 취소됩니다. 일부 작업만 완료되는 상태는 허용되지 않습니다.
- Consistency (일관성):
- 트랜잭션이 완료된 후 데이터베이스는 일관된 상태를 유지해야 합니다.
- Isolation (고립성):
- 동시에 실행되는 트랜잭션이 서로 영향을 주지 않아야 합니다.
- Durability (지속성):
- 트랜잭션이 성공적으로 완료되면, 시스템 오류가 발생해도 결과가 보존됩니다.
은행 계좌 이체 예제
은행에서 사용자 A가 사용자 B에게 돈을 이체한다고 가정해봅시다. 이 작업은 다음 두 단계로 이루어집니다:
- 사용자 A의 계좌에서 돈을 차감.
- 사용자 B의 계좌에 돈을 추가.
이 두 작업은 반드시 동시에 성공하거나 실패해야 합니다. 만약 사용자 A의 계좌에서 돈이 차감되었지만 사용자 B의 계좌에 돈이 추가되지 않았다면, 데이터베이스의 일관성이 깨집니다.
PostgreSQL 트랜잭션 사용법
1. 트랜잭션 시작: BEGIN
- 트랜잭션은
BEGIN명령으로 시작합니다. - 트랜잭션이 시작되면, 해당 블록 내에서 실행되는 모든 작업은 임시 상태로 유지됩니다.
2. 작업 완료 및 저장: COMMIT
COMMIT명령을 실행하면 트랜잭션 내의 모든 작업이 데이터베이스에 반영됩니다.
3. 작업 취소: ROLLBACK
ROLLBACK명령을 실행하면 트랜잭션 내의 모든 작업이 취소되고, 데이터베이스 상태는 트랜잭션 이전으로 복구됩니다.
은행 계좌 이체 트랜잭션 예제
아래는 사용자 A가 사용자 B에게 1000원을 이체하는 트랜잭션 예제입니다.
테이블 구조:
CREATE TABLE accounts (
account_id SERIAL PRIMARY KEY,
account_holder VARCHAR(100),
balance NUMERIC(15, 2)
);
초기 데이터:
INSERT INTO accounts (account_holder, balance) VALUES
('A', 5000.00),
('B', 3000.00);
트랜잭션 쿼리:
-- 트랜잭션 시작
BEGIN;
-- 사용자 A의 계좌에서 1000원을 차감
UPDATE accounts
SET balance = balance - 1000
WHERE account_holder = 'A';
-- 사용자 B의 계좌에 1000원을 추가
UPDATE accounts
SET balance = balance + 1000
WHERE account_holder = 'B';
-- 트랜잭션 완료 (커밋)
COMMIT;
ROLLBACK 사용 예제
만약 트랜잭션 중 오류가 발생하면, 작업을 취소할 수 있습니다.
-- 트랜잭션 시작
BEGIN;
-- 사용자 A의 계좌에서 1000원을 차감
UPDATE accounts
SET balance = balance - 1000
WHERE account_holder = 'A';
-- 오류 발생 (예: 사용자 B 계좌가 존재하지 않음)
UPDATE accounts
SET balance = balance + 1000
WHERE account_holder = 'C'; -- 오류: 'C' 계정 없음
-- 작업 취소 (롤백)
ROLLBACK;
결과:
- 사용자 A의 계좌에서 차감된 1000원이 복구됩니다.
- 데이터베이스 상태는 트랜잭션 이전 상태로 복원됩니다.
PostgreSQL 트랜잭션 관리 명령어
| 명령어 | 설명 |
|---|---|
BEGIN |
트랜잭션 시작. 이후 실행되는 명령은 트랜잭션 내부에서 처리됨. |
COMMIT |
트랜잭션을 종료하고, 모든 변경 사항을 데이터베이스에 반영. |
ROLLBACK |
트랜잭션을 종료하고, 트랜잭션 내의 모든 변경 사항을 취소. |
SAVEPOINT |
트랜잭션 내에서 중간 저장점 생성. 특정 시점으로 되돌릴 수 있음. |
RELEASE |
SAVEPOINT을 삭제하여 메모리 사용을 줄임. |
ROLLBACK TO |
지정된 SAVEPOINT으로 트랜잭션을 되돌림. |
SAVEPOINT 예제
SAVEPOINT를 사용하면 트랜잭션 내에서 특정 지점으로 되돌릴 수 있습니다.
-- 트랜잭션 시작
BEGIN;
-- 사용자 A의 계좌에서 1000원을 차감
UPDATE accounts
SET balance = balance - 1000
WHERE account_holder = 'A';
-- 중간 저장점 생성
SAVEPOINT deduct_done;
-- 사용자 B의 계좌에 1000원을 추가
UPDATE accounts
SET balance = balance + 1000
WHERE account_holder = 'B';
-- 오류 발생, 저장점으로 롤백
ROLLBACK TO deduct_done;
-- 트랜잭션 완료
COMMIT;
결과:
- 사용자 A의 계좌에서 차감된 1000원만 반영되고, 사용자 B의 계좌에는 아무런 변화도 없습니다.
트랜잭션 활용 시 주의사항
- 동시성 문제:
- 여러 트랜잭션이 동시에 실행될 경우, 교착 상태(Deadlock)가 발생할 수 있으므로 주의해야 합니다.
- Isolation Level 설정:
- PostgreSQL은 트랜잭션 간 데이터 고립 수준을 설정할 수 있습니다(
READ COMMITTED,REPEATABLE READ,SERIALIZABLE등).
- PostgreSQL은 트랜잭션 간 데이터 고립 수준을 설정할 수 있습니다(
- 트랜잭션 범위 제한:
- 트랜잭션이 너무 오래 실행되면 다른 사용자나 트랜잭션에 영향을 줄 수 있으므로 범위를 제한해야 합니다.
트랜잭션의 주요 활용 사례
- 은행 시스템:
- 계좌 이체, 예금 및 인출 작업.
- 전자상거래:
- 주문 생성, 결제, 재고 업데이트.
- 데이터베이스 유지 보수:
- 대량 데이터 처리 및 데이터 이관 작업.
요약
- PostgreSQL의 트랜잭션은 데이터베이스의 일관성과 무결성을 보장하는 핵심 도구입니다.
- BEGIN으로 시작하고, 작업 완료 시 COMMIT 또는 작업 취소 시 ROLLBACK으로 종료합니다.
- 오류 발생 시 데이터를 안전하게 복원할 수 있으며, SAVEPOINT를 사용해 세밀한 제어가 가능합니다.
- 이를 통해 중요한 작업(예: 은행 이체)에서 신뢰성을 확보할 수 있습니다.
Schema Migrations
강의 내용
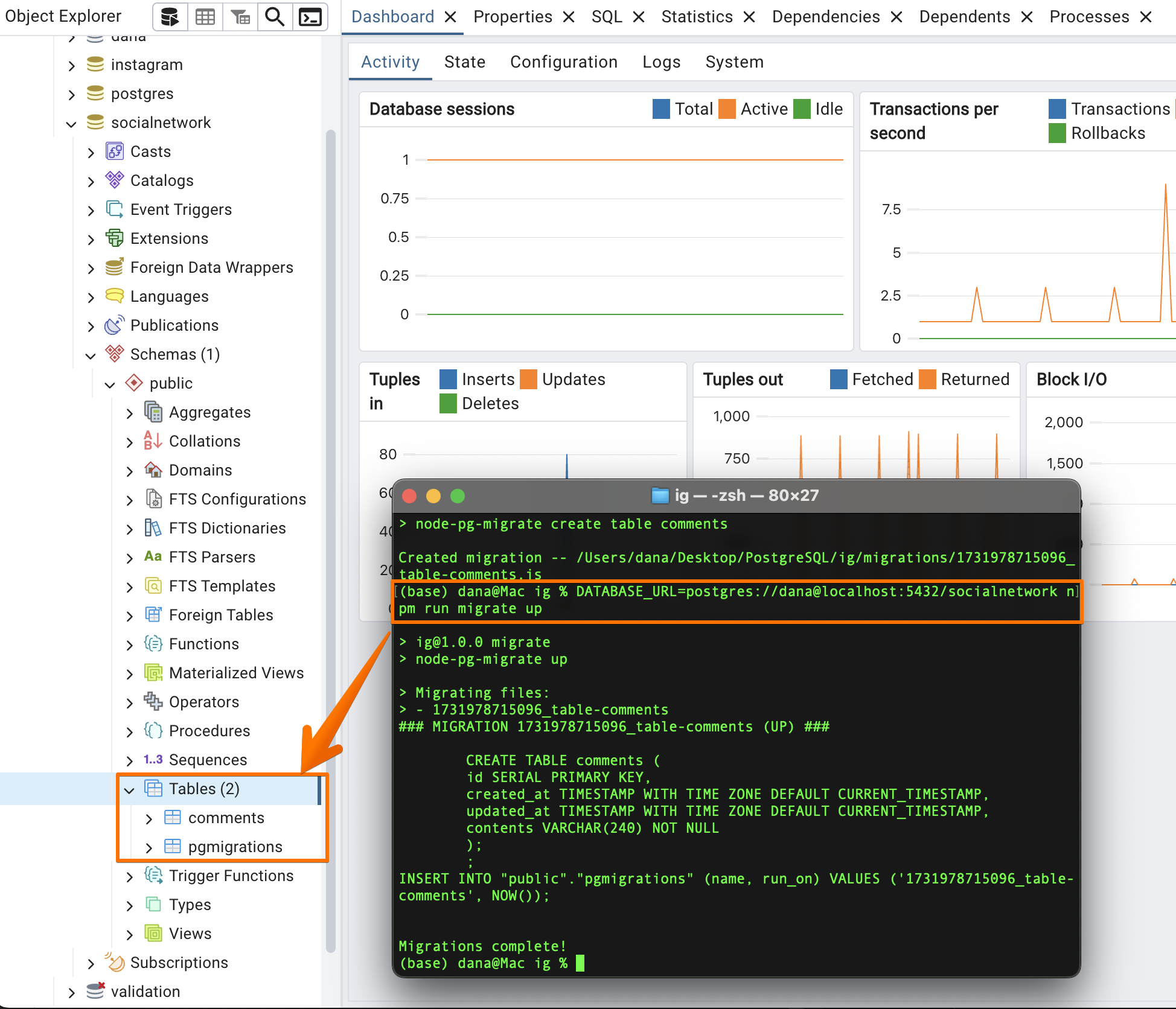
- 폴더 생성
- 폴더 터미널 열어서
npm init -y
npm install node-pg-migrate pg
npm run migrate create table comments - VS Code - package.json 열어서
"scripts": { "migrate": "node-pg-migrate" },로 변경 -
migrations 안의 파일에 테이블 생성, 드랍코드 작성
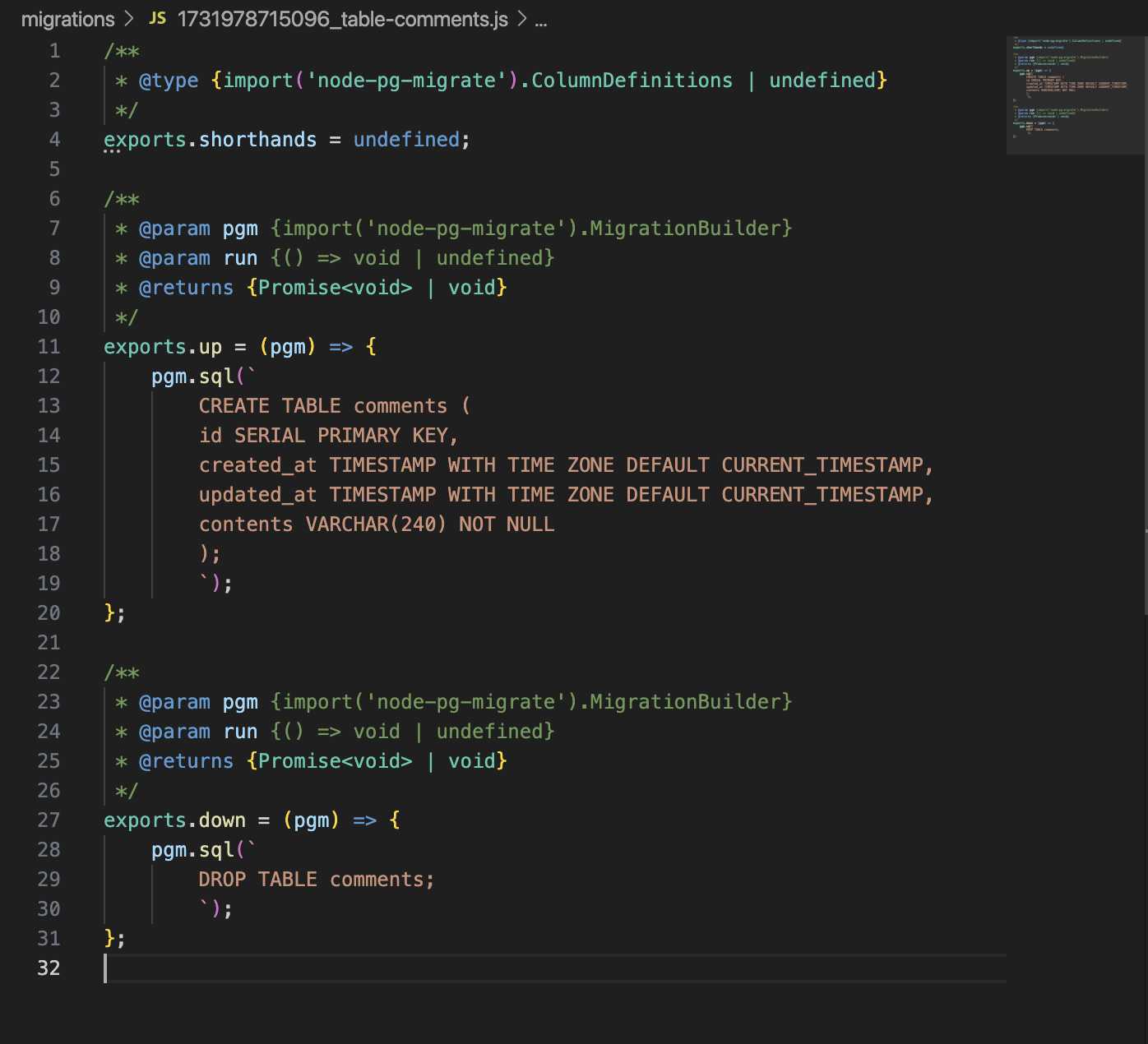
- 터미널에
DATABASE_URL=postgres://dana@localhost:5432/socialnetwork npm run migrate up(<- up or down 선택해서)
✅ 스키마 마이그레이션(Schema Migration)과 데이터 마이그레이션(Data Migration)을 동시에 진행하는 것이 권장되지 않는 이유
1. 스키마 마이그레이션 vs 데이터 마이그레이션의 차이
스키마 마이그레이션:
- 데이터베이스 구조(테이블, 컬럼, 인덱스, 제약 조건 등)를 변경하거나 확장하는 작업.
- 예: 새로운 테이블 추가, 컬럼 타입 변경, 제약 조건 추가.
데이터 마이그레이션:
- 데이터베이스 내의 데이터를 변환하거나, 다른 데이터베이스로 옮기는 작업.
- 예: 데이터를 새로운 스키마에 맞게 변환, 특정 열 값을 계산해서 새 열에 저장.
2. 동시에 진행하면 안 좋은 이유
1) 의존성 문제
- 스키마 마이그레이션이 완료되기 전에 데이터 마이그레이션을 시작하면, 새로운 스키마와 맞지 않는 데이터가 삽입되거나 오류가 발생할 수 있습니다.
- 예: 스키마 변경으로 새로운 제약 조건이 추가되었을 때, 기존 데이터가 그 제약 조건을 만족하지 않아 삽입/변환이 실패할 가능성.
2) 문제 발생 시 디버깅이 어려움
- 스키마와 데이터 모두 동시에 변경하면, 오류의 원인을 파악하기가 어려워집니다.
- 예: 데이터 변환 오류인지, 스키마 변경 문제인지 분리하기가 힘듦.
- 문제를 디버깅하고 해결하는 데 시간이 더 많이 소요됩니다.
3) 업데이트 중단 가능성
- 둘 다 동시 실행하면 데이터베이스가 중간 상태에 머무르게 될 가능성이 있습니다.
- 예: 스키마가 변경되었지만 데이터가 새 스키마와 맞지 않아 애플리케이션이 데이터베이스를 사용하지 못하는 상황.
4) 롤백이 복잡해짐
- 문제가 발생했을 때, 스키마와 데이터 둘 다 롤백해야 하는 상황이 되면 더 복잡하고 위험합니다.
- 예: 스키마를 롤백했는데 데이터 마이그레이션으로 이미 데이터가 변경되었으면, 데이터 불일치 문제가 발생할 수 있음.
5) 운영 환경에서의 서비스 중단 가능성
- 운영 환경에서 두 작업을 동시에 실행하면, 데이터베이스의 가용성이 낮아질 수 있습니다.
- 예: 스키마 변경으로 인한 잠금(lock)이 발생하거나, 데이터 마이그레이션 작업이 과도한 자원을 사용하여 성능 저하를 유발.
3. 권장되는 방법
1) 단계별 실행
- 스키마 마이그레이션과 데이터 마이그레이션을 별도로 진행하는 것이 좋습니다.
- 1단계: 스키마 마이그레이션을 먼저 실행하여 데이터 구조를 준비.
- 2단계: 데이터 마이그레이션을 실행하여 데이터를 변환.
2) 스키마 변경 시 호환성 고려
- 스키마를 변경할 때, 기존 데이터와 새 데이터가 모두 호환될 수 있도록 설계해야 합니다.
- 예: 새로운 컬럼을 추가하되, 기본값을 설정하거나, 기존 애플리케이션이 영향을 받지 않도록 조치.
3) 점진적 데이터 마이그레이션
- 데이터 마이그레이션을 한 번에 하지 않고, 점진적으로 처리하여 작업 중 문제를 감지하고 해결.
- 예: 백그라운드 작업으로 데이터를 변환하면서 기존 스키마와 새 스키마를 동시에 지원.
4) 테스트 환경에서 철저히 검증
- 운영 환경에 적용하기 전에, 테스트 환경에서 스키마 변경 및 데이터 마이그레이션 작업을 별도로 검증합니다.
5) 롤백 계획 마련
- 스키마 마이그레이션과 데이터 마이그레이션 각각에 대해 별도의 롤백 계획을 수립합니다.
4. 예제 시나리오
상황:
기존 users 테이블에 full_name 컬럼을 새로 추가하고, first_name과 last_name 데이터를 합쳐서 채워야 하는 경우.
잘못된 방식 (동시 진행):
- 스키마 변경:
ALTER TABLE users ADD COLUMN full_name VARCHAR(255); - 데이터 마이그레이션:
UPDATE users SET full_name = first_name || ' ' || last_name; - 문제가 발생하면:
- 데이터 불일치로 인해 오류 발생 가능.
권장되는 방식:
- 단계 1: 스키마 변경 (서비스 중단 없음)
ALTER TABLE users ADD COLUMN full_name VARCHAR(255);- 애플리케이션은 여전히 기존
first_name과last_name을 사용 가능.
- 애플리케이션은 여전히 기존
- 단계 2: 데이터 마이그레이션 (점진적 변환)
UPDATE users SET full_name = first_name || ' ' || last_name WHERE full_name IS NULL; - 단계 3: 애플리케이션 업데이트:
- 애플리케이션이
full_name컬럼을 사용하도록 변경.
- 애플리케이션이
- 단계 4: 기존 컬럼 제거 (선택적):
ALTER TABLE users DROP COLUMN first_name, DROP COLUMN last_name;
5. 요약
- 스키마 마이그레이션과 데이터 마이그레이션은 성격과 작업 대상이 다르기 때문에 동시에 진행하면 문제를 야기할 가능성이 높습니다.
- 이를 방지하려면:
- 스키마와 데이터를 분리하여 작업.
- 작업마다 테스트와 롤백 계획을 수립.
- 점진적 방식으로 안전하게 진행.
이러한 접근 방식을 따르면, 서비스 중단을 최소화하면서 안정적인 마이그레이션을 수행할 수 있습니다.
Accessing PostgreSQL From API’s
강의내용
-
폴더 생성, 초기화
mkdir api > cd api > mkdir social-repo > cd social-repo >npm init -y -
종속성 설치
npm install dedent express jest node-pg-mirate nodemon pg pg-format supertest -
VS Code > package.json > script 부분을
"scripts" : { "migrate": "node-pg-migrate", "start": "nodemon index.js" }로 변경 -
마이그레이션 생성
npm run migrate create add users table - 생성된 마이그레이션 파일 안에 테이블 생성
- pgAdmin으로 가서 테이블 생성(테이블명 예: socialnetwork)
-
터미널에
DATABASE_URL=postgres://dana@localhost:5432/socialnetwork npm run migrate up - express관련코드 강의 섹션 33 / 256참조
Building the Users Router
사용자 관리 API
| Route | Method | Goal |
|---|---|---|
/users |
GET | 모든 사용자 목록 가져오기 |
/users/:id |
GET | 특정 사용자 정보 가져오기 |
/users |
POST | 새로운 사용자 생성 |
/users/:id |
PUT | 특정 사용자의 정보 전체 업데이트 |
/users/:id |
PATCH | 특정 사용자의 정보 부분 업데이트 |
/users/:id |
DELETE | 특정 사용자 삭제 |
구현 코드:
const express = require('express');
const app = express();
app.use(express.json()); // JSON 요청 처리
// 1. 모든 사용자 가져오기
app.get('/users', (req, res) => {
res.send('모든 사용자 목록');
});
// 2. 특정 사용자 가져오기
app.get('/users/:id', (req, res) => {
const userId = req.params.id;
res.send(`사용자 ${userId}의 정보`);
});
// 3. 사용자 생성
app.post('/users', (req, res) => {
const newUser = req.body;
res.send(`새로운 사용자 생성: ${JSON.stringify(newUser)}`);
});
// 4. 사용자 전체 업데이트
app.put('/users/:id', (req, res) => {
const userId = req.params.id;
const updatedUser = req.body;
res.send(`사용자 ${userId} 전체 업데이트: ${JSON.stringify(updatedUser)}`);
});
// 5. 사용자 부분 업데이트
app.patch('/users/:id', (req, res) => {
const userId = req.params.id;
const partialUpdate = req.body;
res.send(`사용자 ${userId} 부분 업데이트: ${JSON.stringify(partialUpdate)}`);
});
// 6. 사용자 삭제
app.delete('/users/:id', (req, res) => {
const userId = req.params.id;
res.send(`사용자 ${userId} 삭제`);
});
// 서버 시작
app.listen(3000, () => {
console.log('서버가 3000번 포트에서 실행 중입니다.');
});
✅ Express와 pg(node-postgres)의 Pool 객체를 사용해서 데이터베이스와 연결하는 방법
Express와 pg (node-postgres)의 Pool 객체를 사용하여 PostgreSQL 데이터베이스와 연결하는 방법을 단계별로 설명하겠습니다.
1. 필요한 패키지 설치
Node.js 프로젝트를 설정하고 필요한 패키지를 설치합니다.
명령어:
npm init -y
npm install express pg
express: Node.js의 경량 웹 프레임워크.pg: PostgreSQL과 연결하기 위한 Node.js용 클라이언트 라이브러리.
2. PostgreSQL 데이터베이스 설정
PostgreSQL 데이터베이스를 설정하고 테스트용 테이블과 데이터를 만듭니다.
PostgreSQL 테이블 생성 예제:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE
);
INSERT INTO users (name, email)
VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com');
3. 프로젝트 디렉토리 구조
.
├── index.js # 메인 파일
├── package.json
4. Pool 객체 생성
Pool 객체는 연결 풀(connection pool)을 생성하여 다수의 데이터베이스 요청을 효율적으로 처리합니다.
index.js 파일에 Pool 설정 추가:
const express = require('express');
const { Pool } = require('pg');
// PostgreSQL Pool 설정
const pool = new Pool({
user: 'your_username', // PostgreSQL 사용자 이름
host: 'localhost', // PostgreSQL 서버 주소
database: 'your_database', // 데이터베이스 이름
password: 'your_password', // PostgreSQL 비밀번호
port: 5432 // PostgreSQL 기본 포트
});
// Express 앱 초기화
const app = express();
app.use(express.json()); // JSON 요청 처리
5. API 라우팅 설정
Express를 사용해 간단한 API를 설정하여 데이터베이스와 통신합니다.
1) 모든 사용자 가져오기
app.get('/users', async (req, res) => {
try {
const result = await pool.query('SELECT * FROM users');
res.json(result.rows); // 데이터베이스 결과를 클라이언트에 반환
} catch (err) {
console.error(err);
res.status(500).send('데이터베이스 오류');
}
});
2) 특정 사용자 가져오기
app.get('/users/:id', async (req, res) => {
const userId = req.params.id;
try {
const result = await pool.query('SELECT * FROM users WHERE id = $1', [userId]);
if (result.rows.length === 0) {
return res.status(404).send('사용자를 찾을 수 없습니다.');
}
res.json(result.rows[0]); // 단일 사용자 반환
} catch (err) {
console.error(err);
res.status(500).send('데이터베이스 오류');
}
});
3) 새 사용자 추가
app.post('/users', async (req, res) => {
const { name, email } = req.body;
try {
const result = await pool.query(
'INSERT INTO users (name, email) VALUES ($1, $2) RETURNING *',
[name, email]
);
res.status(201).json(result.rows[0]); // 생성된 사용자 반환
} catch (err) {
console.error(err);
if (err.code === '23505') { // PostgreSQL UNIQUE 제약 조건 위반
res.status(400).send('이메일이 이미 사용 중입니다.');
} else {
res.status(500).send('데이터베이스 오류');
}
}
});
4) 사용자 삭제
app.delete('/users/:id', async (req, res) => {
const userId = req.params.id;
try {
const result = await pool.query('DELETE FROM users WHERE id = $1 RETURNING *', [userId]);
if (result.rows.length === 0) {
return res.status(404).send('사용자를 찾을 수 없습니다.');
}
res.json(result.rows[0]); // 삭제된 사용자 반환
} catch (err) {
console.error(err);
res.status(500).send('데이터베이스 오류');
}
});
6. 서버 실행
Express 서버를 실행하여 API를 사용할 수 있습니다.
index.js에 추가:
// 서버 실행
const PORT = 3000;
app.listen(PORT, () => {
console.log(`서버가 http://localhost:${PORT}에서 실행 중입니다.`);
});
서버 실행 명령:
node index.js
7. API 테스트
Postman, cURL, 또는 브라우저를 사용하여 API를 테스트합니다.
예:
- 모든 사용자 가져오기:
- GET
http://localhost:3000/users
- GET
- 특정 사용자 가져오기:
- GET
http://localhost:3000/users/1
- GET
- 새 사용자 추가:
- POST
http://localhost:3000/users - Body (JSON):
{ "name": "Charlie", "email": "charlie@example.com" }
- POST
- 사용자 삭제:
- DELETE
http://localhost:3000/users/1
- DELETE
8. 요약
pg모듈의Pool객체로 PostgreSQL 연결 풀 설정.- Express로 라우팅 설정하여 HTTP 요청 처리.
- 각 요청에서 SQL 쿼리를 실행하여 데이터베이스와 상호작용.
- 클라이언트 요청을 처리하고 결과를 반환.
✅ Pool이란?
Pool(연결 풀)은 PostgreSQL과 같은 데이터베이스에 다수의 클라이언트 요청을 효율적으로 처리하기 위해 만들어진 연결 관리 기법입니다. Pool은 Node.js에서 pg 라이브러리의 기능으로 제공되며, 여러 데이터베이스 연결을 재사용하거나 동시 요청을 관리하는 데 도움을 줍니다.
1. Pool의 개념
- Pool(연결 풀)은 일정 수의 데이터베이스 연결을 미리 생성해 두고, 요청이 들어오면 이 연결을 할당하여 처리한 후 다시 반환하는 구조입니다.
- 각 요청마다 새로운 연결을 생성하지 않고, 기존 연결을 재사용하기 때문에 성능이 향상됩니다.
2. Pool의 작동 방식
- 초기화:
- 애플리케이션이 시작되면, 설정된 크기만큼의 연결(Connection)이 생성됩니다.
- 요청 처리:
- 데이터베이스 요청이 들어오면, Pool에서 사용 가능한 연결을 제공하고 요청을 처리합니다.
- 반환:
- 요청 처리가 끝나면 연결은 Pool로 반환되어 재사용됩니다.
- 동시성 관리:
- 연결이 부족하면 요청은 대기열에 들어가며, 연결이 반환되면 대기열에서 처리됩니다.
3. Pool의 장점
- 성능 향상:
- 각 요청마다 새로운 연결을 생성하는 비용을 줄이고, 이미 생성된 연결을 재사용하여 처리 속도가 빠릅니다.
- 동시 요청 처리:
- 여러 클라이언트의 요청을 효율적으로 처리할 수 있습니다.
- 리소스 관리:
- 최대 연결 수를 제한하여 데이터베이스 과부하를 방지합니다.
- 간편한 연결 관리:
- 연결 생성과 반환을 Pool이 자동으로 처리하므로 개발자가 직접 관리할 필요가 없습니다.
4. pg.Pool의 주요 설정
pg.Pool 객체는 다양한 설정을 통해 연결 풀의 동작을 제어할 수 있습니다.
기본 설정:
const { Pool } = require('pg');
const pool = new Pool({
user: 'your_username', // PostgreSQL 사용자 이름
host: 'localhost', // 데이터베이스 서버 주소
database: 'your_database', // 데이터베이스 이름
password: 'your_password', // 사용자 비밀번호
port: 5432, // PostgreSQL 기본 포트
max: 10, // 최대 연결 수
idleTimeoutMillis: 30000, // 연결이 사용되지 않을 때 반환되기까지의 시간(밀리초)
connectionTimeoutMillis: 2000 // 새 연결을 생성하는 데 걸리는 최대 시간(밀리초)
});
주요 설정 옵션:
max:- 풀에서 유지할 최대 연결 수.
- 기본값은
10입니다.
idleTimeoutMillis:- 사용되지 않은 연결이 반환되기까지의 시간(밀리초).
- 기본값은
30000(30초).
connectionTimeoutMillis:- 새 연결을 생성하는 데 걸리는 최대 시간(밀리초).
- 기본값은
0(무제한 대기).
min:- 풀에서 유지할 최소 연결 수.
- 기본값은
0입니다.
5. pg.Pool 사용 예제
1) Pool 생성
const { Pool } = require('pg');
// Pool 객체 생성
const pool = new Pool({
user: 'postgres',
host: 'localhost',
database: 'example_db',
password: 'password123',
port: 5432,
max: 10,
idleTimeoutMillis: 30000,
connectionTimeoutMillis: 2000
});
2) 간단한 쿼리 실행
pool.query('SELECT NOW()', (err, res) => {
if (err) {
console.error('쿼리 실행 중 오류:', err);
} else {
console.log('현재 시간:', res.rows);
}
pool.end(); // 연결 풀 종료
});
3) 비동기/대기 패턴 (async/await)
async/await를 사용하면 코드가 더 깔끔해집니다.
(async () => {
try {
const res = await pool.query('SELECT * FROM users');
console.log('사용자 목록:', res.rows);
} catch (err) {
console.error('데이터베이스 오류:', err);
} finally {
pool.end(); // 연결 풀 종료
}
})();
4) Pool 연결 가져오기
pool.connect()를 사용해 Pool에서 개별 연결을 가져올 수 있습니다.
(async () => {
const client = await pool.connect(); // Pool에서 연결 가져오기
try {
const res = await client.query('SELECT * FROM users');
console.log('사용자 목록:', res.rows);
} catch (err) {
console.error('쿼리 오류:', err);
} finally {
client.release(); // 사용 후 연결 반환
}
})();
6. Pool 사용 시 주의사항
- 최대 연결 수 설정:
max값을 적절히 설정하여 데이터베이스 서버의 과부하를 방지하세요.- 너무 낮으면 요청이 대기 상태에 빠지고, 너무 높으면 데이터베이스가 과부하됩니다.
- 연결 반환:
pool.connect()로 연결을 가져온 경우 반드시client.release()를 호출하여 풀로 반환해야 합니다.
- 오류 처리:
try...catch구문을 사용하여 오류를 처리하세요. 데이터베이스 연결 중 문제가 발생할 수 있습니다.
- 풀 종료:
- 애플리케이션 종료 시
pool.end()를 호출하여 연결을 정리하세요.
- 애플리케이션 종료 시
7. 장점 및 한계
장점:
- 성능 향상: 연결 생성 및 종료에 따른 비용 감소.
- 동시성 관리: 다중 클라이언트 요청을 효율적으로 처리.
- 개발 간소화: 연결 관리 코드 간소화.
한계:
- Pool 크기를 잘못 설정하면 성능에 부정적 영향을 미칠 수 있음.
- Pool 관리가 부적절하면 연결 누수가 발생할 수 있음.
8. 요약
- Pool(연결 풀)은 데이터베이스 연결을 효율적으로 관리하여 성능을 최적화합니다.
pg.Pool을 사용하면 PostgreSQL과의 다중 요청을 간단히 처리할 수 있습니다.- 올바른 설정(
max,idleTimeoutMillis등)과 적절한 연결 반환(release())으로 안정적인 애플리케이션을 구축할 수 있습니다.
✅ 레포지토리 패턴
비동기와 Pool을 사용한 레포지토리 패턴은 데이터베이스 접근 코드를 구조화하고 관리하기 위한 방법입니다. 레포지토리(Repository) 패턴은 데이터베이스 작업을 추상화하여 비즈니스 로직과 데이터베이스 작업 코드를 분리하는 데 사용됩니다.
레포지토리(Repository)란?
- 레포지토리는 데이터베이스 작업을 추상화한 클래스나 모듈입니다.
- 데이터베이스와 직접 통신하는 대신, 레포지토리 메서드를 호출하여 필요한 데이터를 가져오거나 저장합니다.
- 주요 목표:
- 비즈니스 로직과 데이터 접근 로직 분리.
- 데이터베이스 변경에 대한 코드 영향 최소화.
- 단일 책임 원칙(SRP)을 준수하여 코드 유지보수를 용이하게 함.
비동기와 Pool을 활용한 레포지토리
Node.js와 PostgreSQL을 사용하는 경우:
- 비동기 처리를 통해 데이터베이스 요청을 효율적으로 관리.
pg.Pool을 사용하여 연결 풀을 관리하고 성능을 최적화.
구현 예제
1. 디렉토리 구조
.
├── database # 데이터베이스 관련 설정
│ └── pool.js # 연결 풀 설정
├── repositories # 레포지토리
│ └── userRepository.js # 사용자 관련 데이터 접근 로직
├── services # 비즈니스 로직
│ └── userService.js # 사용자 관련 비즈니스 로직
├── app.js # Express 서버 설정
2. Pool 설정
pool.js: PostgreSQL 연결 풀 설정을 정의합니다.
const { Pool } = require('pg');
const pool = new Pool({
user: 'postgres',
host: 'localhost',
database: 'example_db',
password: 'password123',
port: 5432,
max: 10, // 최대 연결 수
idleTimeoutMillis: 30000, // 연결 비활성화 시간 (밀리초)
connectionTimeoutMillis: 2000 // 연결 생성 타임아웃 (밀리초)
});
module.exports = pool;
3. 레포지토리 작성
userRepository.js: 사용자 관련 데이터베이스 작업을 담당하는 레포지토리.
const pool = require('../database/pool');
class UserRepository {
// 모든 사용자 조회
async getAllUsers() {
const query = 'SELECT * FROM users';
const result = await pool.query(query);
return result.rows; // 결과 행 반환
}
// 특정 사용자 조회
async getUserById(userId) {
const query = 'SELECT * FROM users WHERE id = $1';
const result = await pool.query(query, [userId]);
return result.rows[0]; // 단일 사용자 반환
}
// 사용자 생성
async createUser(name, email) {
const query = 'INSERT INTO users (name, email) VALUES ($1, $2) RETURNING *';
const result = await pool.query(query, [name, email]);
return result.rows[0]; // 생성된 사용자 반환
}
// 사용자 삭제
async deleteUser(userId) {
const query = 'DELETE FROM users WHERE id = $1 RETURNING *';
const result = await pool.query(query, [userId]);
return result.rows[0]; // 삭제된 사용자 반환
}
}
module.exports = new UserRepository();
4. 비즈니스 로직 작성
userService.js: 사용자 관련 비즈니스 로직을 정의.
const userRepository = require('../repositories/userRepository');
class UserService {
async getAllUsers() {
return await userRepository.getAllUsers();
}
async getUserById(userId) {
const user = await userRepository.getUserById(userId);
if (!user) {
throw new Error('사용자를 찾을 수 없습니다.');
}
return user;
}
async createUser(name, email) {
const existingUser = await userRepository.getUserById(email);
if (existingUser) {
throw new Error('이미 존재하는 이메일입니다.');
}
return await userRepository.createUser(name, email);
}
async deleteUser(userId) {
const deletedUser = await userRepository.deleteUser(userId);
if (!deletedUser) {
throw new Error('삭제할 사용자를 찾을 수 없습니다.');
}
return deletedUser;
}
}
module.exports = new UserService();
5. Express 서버와 연결
app.js: Express 서버에서 사용자 API 엔드포인트를 정의.
const express = require('express');
const userService = require('./services/userService');
const app = express();
app.use(express.json());
// 모든 사용자 조회
app.get('/users', async (req, res) => {
try {
const users = await userService.getAllUsers();
res.json(users);
} catch (err) {
res.status(500).send(err.message);
}
});
// 특정 사용자 조회
app.get('/users/:id', async (req, res) => {
try {
const user = await userService.getUserById(req.params.id);
res.json(user);
} catch (err) {
res.status(404).send(err.message);
}
});
// 사용자 생성
app.post('/users', async (req, res) => {
const { name, email } = req.body;
try {
const newUser = await userService.createUser(name, email);
res.status(201).json(newUser);
} catch (err) {
res.status(400).send(err.message);
}
});
// 사용자 삭제
app.delete('/users/:id', async (req, res) => {
try {
const deletedUser = await userService.deleteUser(req.params.id);
res.json(deletedUser);
} catch (err) {
res.status(404).send(err.message);
}
});
// 서버 실행
app.listen(3000, () => {
console.log('서버가 http://localhost:3000 에서 실행 중입니다.');
});
레포지토리 패턴의 장점
- 코드 재사용성:
- 레포지토리를 통해 데이터베이스 접근 코드를 여러 곳에서 재사용할 수 있습니다.
- 비즈니스 로직과 데이터 접근 로직의 분리:
- 비즈니스 로직(Service 레이어)은 데이터베이스 세부 사항을 알 필요가 없습니다.
- 유지보수성:
- 데이터베이스 변경(예: 쿼리 최적화, 테이블 구조 변경) 시, 레포지토리 레이어만 수정하면 됩니다.
- 테스트 용이성:
- 레포지토리를 모킹(mocking)하여 데이터베이스에 실제로 접근하지 않고 테스트할 수 있습니다.
요약
- Pool은 데이터베이스 연결을 관리하고 요청을 효율적으로 처리.
- 비동기 처리를 통해 데이터베이스와 효율적으로 통신.
- 레포지토리 패턴은 데이터 접근 로직을 추상화하여 비즈니스 로직과 분리, 코드의 가독성과 유지보수성을 높임.
- 구조적인 코드 설계를 통해 애플리케이션 확장성과 안정성을 확보합니다.
✅ 서비스와 레포지토리 분리 이유
서비스(Service)와 레포지토리(Repository)를 분리하는 이유는 애플리케이션의 확장성, 유지보수성, 가독성을 높이기 위함입니다. 물론 간단한 애플리케이션에서는 서비스 없이 레포지토리를 바로 사용하는 것이 가능하지만, 규모가 커지거나 복잡해지면 문제가 발생할 수 있습니다. 아래에서 서비스와 레포지토리를 분리하는 이유를 구체적으로 설명하겠습니다.
1. 책임 분리 (Separation of Concerns)
- 레포지토리는 데이터베이스와의 상호작용만을 담당합니다.
- CRUD 작업(데이터 검색, 삽입, 업데이트, 삭제 등)을 수행.
- 데이터베이스 관련 로직이 포함되어야 하므로, 데이터베이스와 강한 결합이 있습니다.
- 서비스는 비즈니스 로직을 담당합니다.
- 데이터베이스 외에 다른 작업(검증, 외부 API 호출, 데이터 가공 등)을 처리.
- 애플리케이션 로직을 캡슐화하여, 레포지토리가 아닌 비즈니스 문제를 해결하는 데 초점을 맞춥니다.
문제점:
- 레포지토리에서 직접 데이터를 가져와도 되지만, 데이터베이스와 관련 없는 비즈니스 로직이 포함되면 레포지토리가 점점 비대해지고 역할이 모호해집니다.
장점:
- 서비스와 레포지토리를 분리하면 각각의 역할을 명확히 구분하여 코드가 더 간결하고 유지보수하기 쉬워집니다.
2. 비즈니스 로직의 재사용성
- 서비스 계층은 비즈니스 로직을 캡슐화하므로, 여러 컨트롤러나 API 엔드포인트에서 동일한 로직을 쉽게 재사용할 수 있습니다.
예:
- 사용자를 생성할 때, 이메일 중복 체크와 이름 길이 검증이 필요하다고 가정.
- 검증 로직이 서비스 계층에 있다면, 이를 재사용할 수 있습니다.
// 서비스 계층
class UserService {
async createUser(name, email) {
if (email.length === 0) {
throw new Error('이메일은 필수입니다.');
}
if (name.length > 50) {
throw new Error('이름이 너무 깁니다.');
}
return await userRepository.createUser(name, email);
}
}
이 로직을 컨트롤러에서 여러 번 반복 작성하는 대신, 서비스 계층에 두면 재사용이 가능하고 코드 중복을 방지할 수 있습니다.
3. 비즈니스 로직과 데이터 접근 로직의 결합 방지
- 레포지토리에는 데이터베이스와 관련된 SQL 쿼리나 ORM 호출만 있어야 합니다.
- 만약 레포지토리에 비즈니스 로직(검증, 데이터 처리 등)이 포함되면:
- 데이터베이스를 변경할 때 비즈니스 로직도 수정해야 함.
- 데이터베이스 독립성이 떨어지고 코드가 비대해짐.
문제점 예:
레포지토리에 검증 로직을 포함하면 다음과 같이 책임이 결합됩니다.
class UserRepository {
async createUser(name, email) {
if (!email.includes('@')) {
throw new Error('이메일 형식이 올바르지 않습니다.');
}
return await pool.query('INSERT INTO users (name, email) VALUES ($1, $2)', [name, email]);
}
}
문제:
- 레포지토리가 비즈니스 로직(이메일 검증)과 데이터베이스 작업(INSERT 쿼리)을 모두 처리.
- 검증 로직이 여러 레포지토리에 중복될 가능성이 있음.
4. 테스트 용이성
서비스 계층을 분리하면 비즈니스 로직과 데이터 접근 로직을 독립적으로 테스트할 수 있습니다.
예:
- 레포지토리는 데이터베이스를 연결한 통합 테스트를 통해 검증.
- 서비스는 레포지토리를 모킹(Mock)하여 비즈니스 로직만 단위 테스트.
const mockUserRepository = {
createUser: jest.fn().mockResolvedValue({ id: 1, name: 'Alice', email: 'alice@example.com' })
};
const userService = new UserService(mockUserRepository);
test('createUser should validate email format', async () => {
await expect(userService.createUser('Alice', 'invalid-email')).rejects.toThrow('이메일 형식이 올바르지 않습니다.');
});
장점:
- 데이터베이스 없이도 서비스 로직을 테스트할 수 있어 개발 속도가 빨라집니다.
5. 확장성과 유지보수성
서비스 계층을 분리하면 애플리케이션 확장과 유지보수가 쉬워집니다.
예:
- 새로운 기능 추가:
- 예: 사용자 생성 시 외부 API 호출 추가.
- 이 로직은 레포지토리 대신 서비스 계층에 추가하여 유지보수성을 높입니다.
class UserService {
async createUser(name, email) {
const user = await userRepository.createUser(name, email);
// 외부 API에 사용자 데이터 전송
await externalApi.sendWelcomeEmail(user.email);
return user;
}
}
6. 서비스 계층 없이 레포지토리만 사용했을 때의 문제점
- 비즈니스 로직 중복:
- 여러 컨트롤러에서 동일한 검증 로직을 반복 작성.
- 유지보수 비용 증가.
- 코드 비대화:
- 레포지토리에 데이터 접근 로직과 비즈니스 로직이 모두 포함되면 코드가 비대하고 복잡해짐.
- 테스트 어려움:
- 데이터베이스에 의존적이므로, 단위 테스트가 어려워지고 테스트 속도가 느려짐.
- 변경 비용 증가:
- 비즈니스 로직이 여러 곳에 분산되어 있으면, 요구사항 변경 시 수정해야 할 코드가 많아짐.
서비스와 레포지토리 분리의 요약
| 구분 | 서비스(Service) | 레포지토리(Repository) |
|---|---|---|
| 책임 | 비즈니스 로직 처리 | 데이터베이스 접근 처리 |
| 포커스 | 검증, 데이터 가공, 외부 API 호출 | SQL 쿼리 또는 ORM 호출 |
| 중점 | 애플리케이션 로직의 재사용성 및 확장성 | 데이터베이스와의 직접 상호작용 |
| 테스트 가능성 | 레포지토리를 모킹하여 단위 테스트 가능 | 데이터베이스 연결이 필요한 통합 테스트 |
결론
- 서비스 계층 없이 레포지토리를 직접 사용하는 것은 작은 프로젝트에서는 가능하지만, 애플리케이션이 커질수록 문제가 발생할 수 있습니다.
- 서비스와 레포지토리를 분리하면 비즈니스 로직과 데이터 접근 로직을 독립적으로 관리할 수 있어 확장성과 유지보수성이 향상됩니다.
- 이는 특히 팀 작업, 코드 재사용성, 테스트 요구가 높은 프로젝트에서 필수적인 설계 방식입니다.
✅ PREPARE, EXECUTE
PREPARE와 EXECUTE는 PostgreSQL에서 SQL 문을 실행하기 전에 준비(Prepare)하여 성능을 최적화하거나 반복적으로 실행할 수 있도록 돕는 기능입니다. 이는 서버 측 준비된 문장(Server-Side Prepared Statements)을 사용하며, 쿼리를 동적으로 실행할 때 유용합니다.
1. PREPARE란?
- SQL 문을 미리 준비(Compile)하고 저장합니다.
- 쿼리를 실행할 때 SQL 구문을 매번 분석하고 최적화하지 않아도 되므로, 성능이 향상됩니다.
- 플레이스홀더($1, $2, …)를 사용하여 동적으로 값을 제공할 수 있습니다.
기본 문법:
PREPARE prepared_name (parameter_types) AS
query;
prepared_name: 준비된 문장의 이름.parameter_types: 파라미터의 데이터 타입 (예:INT,TEXT).query: 실행할 SQL 쿼리. 플레이스홀더를 사용하여 동적 파라미터를 정의.
2. EXECUTE란?
PREPARE로 준비된 문장을 실제로 실행합니다.- 실행 시 동적 파라미터 값을 제공하여 쿼리를 실행합니다.
기본 문법:
EXECUTE prepared_name (parameter_values);
prepared_name: 실행할 준비된 문장의 이름.parameter_values: 실행 시 전달할 값.
3. PREPARE와 EXECUTE 사용 예제
데이터베이스 테이블 준비:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT,
email TEXT
);
INSERT INTO users (name, email)
VALUES ('Alice', 'alice@example.com'), ('Bob', 'bob@example.com');
1) PREPARE로 문장 준비
PREPARE get_user_by_id (INT) AS
SELECT * FROM users WHERE id = $1;
- 설명:
get_user_by_id라는 이름의 준비된 문장을 생성.- 플레이스홀더
$1: 첫 번째 파라미터로 값을 받을 위치를 지정. INT: 파라미터 데이터 타입은 정수.
2) EXECUTE로 실행
EXECUTE get_user_by_id(1);
- 결과:
id | name | email ----+-------+---------------------- 1 | Alice | alice@example.com
3) 다른 값으로 EXECUTE 실행
EXECUTE get_user_by_id(2);
- 결과:
id | name | email ----+-------+---------------------- 2 | Bob | bob@example.com
4. DEALLOCATE로 준비된 문장 삭제
PREPARE로 생성한 문장은 세션 내에서 유지됩니다.- 더 이상 사용하지 않을 경우 삭제하여 리소스를 해제할 수 있습니다.
문법:
DEALLOCATE prepared_name;
예제:
DEALLOCATE get_user_by_id;
get_user_by_id라는 이름의 준비된 문장을 삭제합니다.
5. PREPARE와 EXECUTE를 사용하는 이유
1) 성능 최적화
- SQL 쿼리를 미리 컴파일하고 저장하여 반복 실행 시 성능을 향상.
PREPARE는 쿼리의 파싱, 구문 분석, 최적화를 한 번만 수행.- 이후
EXECUTE시 준비된 쿼리를 실행만 하기 때문에 처리 속도가 더 빠름.
2) 코드 간결화
- 동일한 SQL 쿼리를 반복적으로 실행해야 하는 경우,
PREPARE와EXECUTE를 사용하면 코드가 간결해지고 유지보수도 쉬워짐.
3) SQL 인젝션 방지
- 파라미터화된 쿼리를 사용하여 SQL 인젝션 공격 방지.
- 값은 플레이스홀더(
$1,$2등)를 통해 전달되며, PostgreSQL이 안전하게 처리.
- 값은 플레이스홀더(
6. 고급 사용법
1) 여러 파라미터 사용:
PREPARE get_user_by_email (TEXT, INT) AS
SELECT * FROM users WHERE email = $1 AND id = $2;
EXECUTE get_user_by_email('alice@example.com', 1);
2) 동적 INSERT 문:
PREPARE insert_user (TEXT, TEXT) AS
INSERT INTO users (name, email) VALUES ($1, $2);
EXECUTE insert_user('Charlie', 'charlie@example.com');
7. 주의 사항
- 세션 내에서만 유지:
PREPARE로 준비된 문장은 해당 데이터베이스 세션에서만 유효합니다.- 세션이 종료되면 준비된 문장이 사라집니다.
- 동적 쿼리에는 적합하지 않음:
- 준비된 문장은 SQL 구조가 고정되어야 하며, WHERE 조건이나 ORDER BY 등 쿼리 구조 자체를 동적으로 변경할 수는 없습니다.
- 과도한 사용 방지:
- 많은 문장을 준비하면 메모리 리소스가 낭비될 수 있으므로 필요 없는 준비된 문장은
DEALLOCATE로 삭제해야 합니다.
- 많은 문장을 준비하면 메모리 리소스가 낭비될 수 있으므로 필요 없는 준비된 문장은
8. PREPARE와 일반 쿼리 비교
| 특징 | PREPARE + EXECUTE | 일반 쿼리 |
|---|---|---|
| 컴파일 | 한 번만 수행 | 매번 컴파일 |
| 성능 | 반복 실행 시 더 빠름 | 단일 실행에 적합 |
| SQL 인젝션 방지 | 파라미터화된 쿼리로 안전 | 매번 수동으로 파라미터 처리 필요 |
| 유연성 | 쿼리 구조가 고정됨 | 유연하게 쿼리 구조 변경 가능 |
9. 요약
PREPARE: SQL 문을 미리 준비(컴파일)하여 저장.EXECUTE: 준비된 문장을 실행하며 동적 파라미터 값을 전달.- 장점:
- 성능 최적화 (반복 실행 시).
- SQL 인젝션 방지.
- 코드 간결화.
- 주의:
- 쿼리 구조는 고정되어야 하며, 세션 종료 시 준비된 문장이 사라집니다.
PREPARE와 EXECUTE는 반복적으로 실행되는 SQL 쿼리가 많거나, 성능 최적화와 보안이 중요한 환경에서 매우 유용합니다.
✅A Note on Testing
Jest는 JavaScript에서 가장 널리 사용되는 테스팅 프레임워크 중 하나로, 데이터베이스 테스트에서도 활용할 수 있습니다. PostgreSQL 같은 데이터베이스와 Jest를 통합하여 테스트를 수행하면, 애플리케이션의 데이터베이스 관련 코드가 정확히 동작하는지 확인할 수 있습니다.
1. 데이터베이스 테스트의 목적
- CRUD 작업 테스트:
- 데이터 삽입, 조회, 업데이트, 삭제가 제대로 동작하는지 확인.
- 데이터 무결성 검증:
- 제약 조건(Constraints)이 올바르게 작동하는지 확인.
- 복잡한 쿼리 로직 테스트:
- JOIN, GROUP BY, ORDER BY 등 복잡한 쿼리가 예상한 결과를 반환하는지 검증.
- 트랜잭션 및 에러 처리 확인:
- 트랜잭션 롤백, 예외 처리 로직 등이 예상대로 동작하는지 확인.
2. 테스트 환경 설정
1) Jest 설치
테스팅 프레임워크인 Jest를 설치합니다.
npm install --save-dev jest
npm install --save-dev @types/jest # TypeScript 사용 시
2) PostgreSQL 클라이언트 설치
PostgreSQL 데이터베이스와 상호작용하기 위해 pg를 설치합니다.
npm install pg
3) 데이터베이스 테이블 및 테스트 데이터 준비
테스트를 위한 데이터베이스와 샘플 데이터를 준비합니다.
테이블 생성 예제:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL
);
샘플 데이터 삽입:
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com');
3. Jest와 PostgreSQL 테스트 구조
디렉토리 구조:
.
├── src/
│ ├── database/
│ │ └── pool.js # PostgreSQL 연결 풀 설정
│ ├── repositories/
│ │ └── userRepository.js # 데이터베이스 작업 (CRUD)
├── tests/
│ ├── setup.js # 테스트 환경 설정 (초기화)
│ ├── teardown.js # 테스트 환경 종료
│ ├── userRepository.test.js # 사용자 레포지토리 테스트
├── jest.config.js # Jest 설정 파일
├── package.json
4. PostgreSQL 연결 풀 설정
src/database/pool.js: PostgreSQL 연결 풀을 생성.
const { Pool } = require('pg');
const pool = new Pool({
user: 'postgres',
host: 'localhost',
database: 'test_db', // 테스트 전용 데이터베이스
password: 'password123',
port: 5432,
});
module.exports = pool;
5. 레포지토리 작성
src/repositories/userRepository.js: 사용자 관련 데이터베이스 작업을 정의.
const pool = require('../database/pool');
class UserRepository {
async getAllUsers() {
const result = await pool.query('SELECT * FROM users');
return result.rows;
}
async getUserById(id) {
const result = await pool.query('SELECT * FROM users WHERE id = $1', [id]);
return result.rows[0];
}
async createUser(name, email) {
const result = await pool.query(
'INSERT INTO users (name, email) VALUES ($1, $2) RETURNING *',
[name, email]
);
return result.rows[0];
}
async deleteUser(id) {
const result = await pool.query('DELETE FROM users WHERE id = $1 RETURNING *', [id]);
return result.rows[0];
}
}
module.exports = new UserRepository();
6. Jest 테스트 설정
1) Jest 초기화 및 종료 설정
tests/setup.js: 데이터베이스 초기화.
const pool = require('../src/database/pool');
beforeAll(async () => {
await pool.query('CREATE TABLE IF NOT EXISTS users (id SERIAL PRIMARY KEY, name TEXT, email TEXT UNIQUE)');
await pool.query('TRUNCATE TABLE users RESTART IDENTITY');
await pool.query("INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com'), ('Bob', 'bob@example.com')");
});
afterAll(async () => {
await pool.query('DROP TABLE IF EXISTS users');
await pool.end();
});
Jest 설정 파일:
jest.config.js: Jest 설정 파일.
module.exports = {
setupFilesAfterEnv: ['./tests/setup.js'], // 테스트 전후 실행할 파일
testEnvironment: 'node', // Node.js 환경에서 실행
};
2) 사용자 레포지토리 테스트
tests/userRepository.test.js: 레포지토리를 테스트하는 코드.
const userRepository = require('../src/repositories/userRepository');
describe('User Repository', () => {
test('모든 사용자를 조회한다.', async () => {
const users = await userRepository.getAllUsers();
expect(users).toHaveLength(2);
expect(users[0]).toMatchObject({ name: 'Alice', email: 'alice@example.com' });
});
test('ID로 특정 사용자를 조회한다.', async () => {
const user = await userRepository.getUserById(1);
expect(user).toMatchObject({ name: 'Alice', email: 'alice@example.com' });
});
test('새로운 사용자를 추가한다.', async () => {
const newUser = await userRepository.createUser('Charlie', 'charlie@example.com');
expect(newUser).toMatchObject({ name: 'Charlie', email: 'charlie@example.com' });
const users = await userRepository.getAllUsers();
expect(users).toHaveLength(3); // 기존 2명 + 새로 추가 1명
});
test('사용자를 삭제한다.', async () => {
const deletedUser = await userRepository.deleteUser(1);
expect(deletedUser).toMatchObject({ name: 'Alice', email: 'alice@example.com' });
const users = await userRepository.getAllUsers();
expect(users).toHaveLength(2); // 삭제 후 남은 사용자 수
});
});
7. 테스트 실행
실행 명령:
npx jest
실행 결과:
PASS tests/userRepository.test.js
User Repository
✓ 모든 사용자를 조회한다. (50ms)
✓ ID로 특정 사용자를 조회한다. (25ms)
✓ 새로운 사용자를 추가한다. (30ms)
✓ 사용자를 삭제한다. (20ms)
Test Suites: 1 passed, 1 total
Tests: 4 passed, 4 total
Snapshots: 0 total
Time: 1.5s
8. 데이터베이스 테스트의 주요 고려사항
- 테스트 데이터 초기화:
- 테스트 전후 데이터베이스 상태를 항상 초기화(
TRUNCATE또는RESTART IDENTITY)하여 테스트 간 간섭을 방지.
- 테스트 전후 데이터베이스 상태를 항상 초기화(
- 테스트 전용 데이터베이스 사용:
- 실제 운영 데이터베이스 대신, 테스트 데이터베이스를 별도로 구성하여 데이터 손상 방지.
- 성능 최적화:
- 데이터베이스 초기화와 종료 속도를 최적화하여 테스트 실행 시간을 줄임.
- 트랜잭션 활용:
- 각 테스트를 트랜잭션으로 감싸고, 테스트 종료 후 롤백하여 데이터 무결성을 유지할 수 있음.
9. 결론
- Jest를 사용한 데이터베이스 테스트는 애플리케이션의 데이터베이스 로직을 안정적으로 검증할 수 있는 강력한 도구입니다.
- 레포지토리 계층과 Jest의 설정 파일을 잘 활용하여, 독립적이고 효율적인 테스트 환경을 구성할 수 있습니다.
- 테스트 환경을 제대로 설정하면, 데이터베이스와의 상호작용에 대한 신뢰성을 높이고, 코드 변경 시 발생할 수 있는 오류를 빠르게 발견할 수 있습니다.
✅ Jest와 병렬테스트
Jest와 PostgreSQL의 병렬 테스트를 설정하려면, 데이터베이스를 각 테스트 워커(worker)마다 독립적으로 사용하도록 구성해야 합니다. 이를 위해 스키마(Schema)를 사용하면, 단일 데이터베이스 내에서 독립적인 환경을 생성할 수 있어, 테스트 간 간섭을 방지하면서 병렬 테스트를 수행할 수 있습니다.
1. 병렬 테스트와 스키마 기반 접근 방식의 개념
- 병렬 테스트 문제:
- Jest는 기본적으로 테스트를 병렬로 실행합니다.
- 동일한 데이터베이스를 사용하면 한 테스트에서 데이터가 변경되었을 때 다른 테스트에 영향을 미칠 수 있습니다.
- 스키마 기반 해결:
- PostgreSQL의 스키마를 사용하여 각 테스트 워커(worker)가 고유한 데이터베이스 환경을 갖도록 설정.
- 워커마다 고유한 스키마를 생성하고, 테스트 종료 후 삭제.
2. 설정 및 구현
1) pgAdmin에서 스키마 추가
- 기본 데이터베이스 생성:
- PostgreSQL 데이터베이스에서 테스트 전용 데이터베이스를 생성.
CREATE DATABASE test_db;
- PostgreSQL 데이터베이스에서 테스트 전용 데이터베이스를 생성.
- pgAdmin을 통해 기본 스키마 설정:
pgAdmin에서 Public Schema 외에 기본 테이블 구조를 담은 초기화 스키마(template_schema)를 생성.- 이 스키마를 각 워커가 복사하여 독립적인 환경을 생성하는 데 사용.
2) 디렉토리 구조
.
├── src/
│ ├── database/
│ │ └── pool.js # PostgreSQL 연결 풀 설정
├── tests/
│ ├── setup.js # 테스트 환경 초기화
│ ├── teardown.js # 테스트 환경 종료
│ ├── userRepository.test.js # 테스트 파일
├── jest.config.js # Jest 설정 파일
3) PostgreSQL 연결 풀 설정
src/database/pool.js: Jest 테스트 워커마다 고유의 스키마를 사용할 수 있도록 설정.
const { Pool } = require('pg');
// Jest 워커마다 고유한 스키마 이름 설정
const schemaName = `test_schema_${process.env.JEST_WORKER_ID}`;
const pool = new Pool({
user: 'postgres',
host: 'localhost',
database: 'test_db', // 테스트 데이터베이스
password: 'password123',
port: 5432,
statement_timeout: 10000, // 쿼리 시간 제한
});
// 각 스키마 설정
async function setupSchema() {
await pool.query(`CREATE SCHEMA IF NOT EXISTS ${schemaName}`);
await pool.query(`SET search_path TO ${schemaName}`);
}
// 스키마 삭제
async function teardownSchema() {
await pool.query(`DROP SCHEMA IF EXISTS ${schemaName} CASCADE`);
}
// 스키마 초기화 및 반환
module.exports = { pool, setupSchema, teardownSchema };
4) Jest 초기화 및 종료
tests/setup.js: 각 워커의 스키마를 초기화.
const { setupSchema } = require('../src/database/pool');
beforeAll(async () => {
await setupSchema();
});
tests/teardown.js: 각 워커의 스키마를 제거.
const { teardownSchema } = require('../src/database/pool');
afterAll(async () => {
await teardownSchema();
});
5) Jest 설정
jest.config.js: Jest 환경 설정.
module.exports = {
setupFilesAfterEnv: ['./tests/setup.js'], // 테스트 초기화 파일
globalTeardown: './tests/teardown.js', // 테스트 종료 파일
testEnvironment: 'node', // Node.js 환경에서 실행
maxWorkers: 4, // 병렬 실행 워커 수
};
6) 레포지토리 테스트
tests/userRepository.test.js: 테스트 간 독립적인 데이터베이스 환경 보장.
const pool = require('../src/database/pool');
describe('User Repository Tests', () => {
beforeAll(async () => {
// 기본 테이블 생성
await pool.query(`
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
`);
});
afterAll(async () => {
// 테이블 삭제
await pool.query('DROP TABLE IF EXISTS users');
});
test('사용자 추가', async () => {
const result = await pool.query(
'INSERT INTO users (name, email) VALUES ($1, $2) RETURNING *',
['Alice', 'alice@example.com']
);
expect(result.rows[0]).toMatchObject({ name: 'Alice', email: 'alice@example.com' });
});
test('사용자 조회', async () => {
const result = await pool.query('SELECT * FROM users');
expect(result.rows).toHaveLength(1);
expect(result.rows[0]).toMatchObject({ name: 'Alice', email: 'alice@example.com' });
});
});
3. 테스트 실행
실행 명령:
npx jest
실행 결과:
PASS tests/userRepository.test.js
User Repository Tests
✓ 사용자 추가 (100ms)
✓ 사용자 조회 (50ms)
Test Suites: 1 passed, 1 total
Tests: 2 passed, 2 total
Snapshots: 0 total
Time: 2.5s
4. 스키마 방식의 장점
- 병렬 테스트 지원:
- 각 워커가 독립적인 스키마를 사용하므로 데이터 충돌 방지.
- 단일 데이터베이스 사용:
- 여러 데이터베이스를 생성하지 않고, 단일 데이터베이스 내에서 스키마로 분리하여 리소스 절약.
- 테스트 환경 복원 용이:
- 스키마를 쉽게 생성 및 삭제하여 테스트 환경 초기화 가능.
5. 주의사항
- 스키마 정리:
- 테스트 종료 후 스키마를 삭제하지 않으면 데이터베이스에 불필요한 스키마가 쌓일 수 있습니다.
- 서버 리소스 관리:
- 병렬 워커 수(
maxWorkers)를 서버 성능에 맞게 설정하세요.
- 병렬 워커 수(
- 트랜잭션 활용:
- 각 테스트 케이스를 트랜잭션으로 감싸고, 테스트 종료 시 롤백하여 초기 상태를 유지할 수 있습니다.
6. 결론
Jest와 PostgreSQL에서 스키마를 활용한 병렬 테스트는 테스트 간 독립성을 유지하면서 데이터 충돌을 방지하는 효과적인 방법입니다. PostgreSQL의 스키마를 사용하여 단일 데이터베이스에서 여러 테스트 워커가 동시에 실행할 수 있는 환경을 만들고, Jest의 설정 파일을 활용해 초기화와 종료 작업을 자동화하면 테스트의 안정성과 효율성을 높일 수 있습니다.
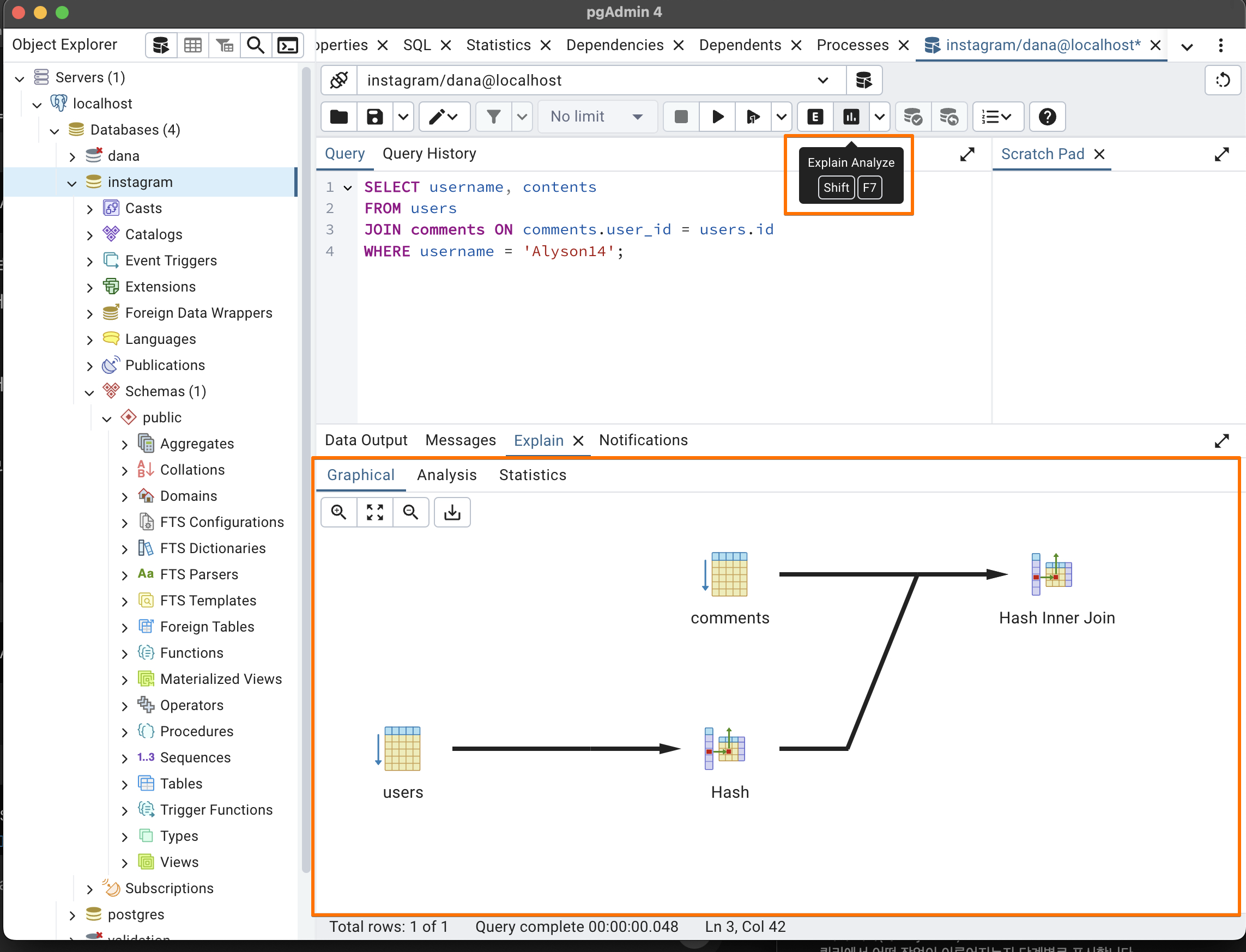 Performance Optimization and Data Exploration Tools
Performance Optimization and Data Exploration Tools