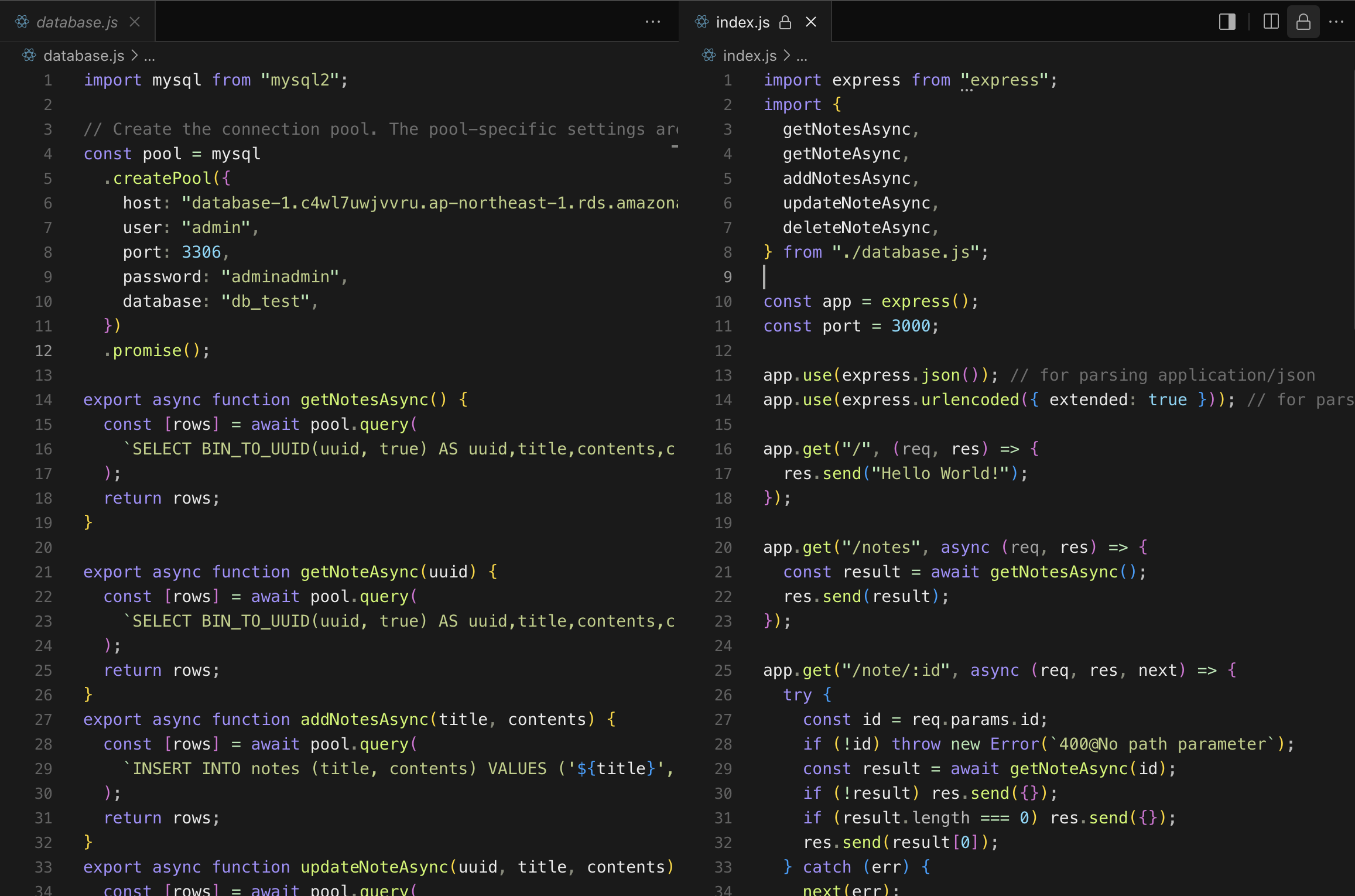
Express
- 설치
npm install express --save - 로컬환경에서 쓸 경우
npx express-generator - 기본 라우팅 https://expressjs.com/en/starter/basic-routing.html
- ReqBin https://reqbin.com : 온라인 API 테스트 도구
주요 HTTP 상태 코드와 의미
201은 HTTP 상태 코드로, 특정 요청에 대해 서버가 클라이언트에 전달하는 표준 응답 메시지 중 하나입니다. 201 Created는 클라이언트의 요청이 성공적으로 처리되었으며, 새로운 리소스가 생성되었음을 나타냅니다.
주요 HTTP 상태 코드와 의미
1xx (정보 응답)
- 100 Continue: 요청이 잘 수신되었으며, 클라이언트가 계속 작업을 진행해도 좋다는 뜻.
- 101 Switching Protocols: 서버가 프로토콜 전환을 허용했다는 뜻.
2xx (성공)
- 200 OK: 요청이 성공적으로 처리되었음.
- 201 Created: 요청이 성공적이며, 새로운 리소스가 생성됨.
- 204 No Content: 요청은 성공적으로 처리되었지만, 반환할 내용이 없음.
3xx (리다이렉션)
- 301 Moved Permanently: 요청한 리소스가 영구적으로 새로운 URL로 이동했음.
- 302 Found: 요청한 리소스가 일시적으로 다른 URL에 있음.
- 304 Not Modified: 클라이언트 캐시에 저장된 리소스가 여전히 유효함.
4xx (클라이언트 오류)
- 400 Bad Request: 잘못된 요청. 서버가 요청을 이해할 수 없음.
- 401 Unauthorized: 인증이 필요하거나, 인증 정보가 유효하지 않음.
- 403 Forbidden: 서버가 요청을 거부했음 (권한 문제).
- 404 Not Found: 요청한 리소스를 찾을 수 없음.
5xx (서버 오류)
- 500 Internal Server Error: 서버 내부에서 문제가 발생했음.
- 501 Not Implemented: 서버가 요청을 처리할 수 있는 기능을 지원하지 않음.
- 503 Service Unavailable: 서버가 일시적으로 사용 불가능함 (예: 과부하, 유지 보수).
Express 미들웨어
-
app.use(express.json());: 미들웨어의 일종으로, Express 애플리케이션에서 JSON 형식의 요청 본문(body)을 파싱하고 req.body 객체에 해당 데이터를 추가해주는 역할 -
app.use(express.urlencoded({ extended: true }));: 미들웨어로, 클라이언트가application/x-www-form-urlencoded형식으로 전송한 URL-encoded 데이터를 파싱하여req.body객체에 저장합니다. 주로 HTML 폼 데이터를 처리할 때 사용됩니다.
1. URL-encoded 데이터란?
URL-encoded 데이터는 HTML 폼에서 주로 사용하는 데이터 인코딩 방식으로, 키-값 쌍으로 데이터를 전송합니다.
예를 들어, 클라이언트가 다음과 같은 HTML 폼을 전송했다고 가정합니다:
<form action="/submit" method="POST">
<input type="text" name="username" value="John">
<input type="text" name="age" value="30">
<button type="submit">Submit</button>
</form>
폼 데이터는 아래와 같은 형식으로 전송됩니다:
username=John&age=30
이 데이터를 서버에서 처리하려면 파싱이 필요하며, express.urlencoded()가 이를 처리합니다.
2. extended 옵션
express.urlencoded({ extended: true })에서 extended 옵션은 중첩 객체 및 배열의 파싱 방식을 결정합니다.
extended: true:qs라이브러리를 사용하여 중첩 객체나 복잡한 데이터 구조를 처리할 수 있음.- 예:
foo[bar]=baz→{ foo: { bar: 'baz' } } - 배열도 파싱 가능:
colors[]=red&colors[]=blue→{ colors: ['red', 'blue'] }
extended: false:querystring라이브러리를 사용하여 단순한 키-값 쌍만 파싱.- 예:
foo[bar]=baz→{ 'foo[bar]': 'baz' } - 중첩 객체나 배열은 처리할 수 없음.
3. 기능
express.urlencoded()는 다음 작업을 수행합니다:
- 폼 데이터를 파싱:
클라이언트가 전송한 URL-encoded 데이터를 읽고, 이를 JavaScript 객체로 변환하여req.body에 저장합니다. - 서버 코드 간소화:
폼 데이터를 처리하기 위한 파싱 로직을 직접 작성하지 않아도 됩니다.
4. 사용 예시
const express = require("express");
const app = express();
// URL-encoded 데이터 파싱 미들웨어
app.use(express.urlencoded({ extended: true }));
app.post("/submit", (req, res) => {
console.log(req.body);
res.send("Data received");
});
app.listen(3000, () => console.log("Server is running on port 3000"));
클라이언트 요청:
폼 데이터를 전송:
POST /submit
Content-Type: application/x-www-form-urlencoded
username=John&age=30
서버 출력:
{
username: 'John',
age: '30'
}
5. extended: true와 extended: false 차이점
중첩 객체를 포함한 데이터 처리:
extended: true:POST /submit Content-Type: application/x-www-form-urlencoded user[name]=John&user[age]=30출력:
{ user: { name: 'John', age: '30' } }extended: false:POST /submit Content-Type: application/x-www-form-urlencoded user[name]=John&user[age]=30출력:
{ 'user[name]': 'John', 'user[age]': '30' }
6. express.urlencoded()와 JSON 처리의 차이점
| 특징 | express.json() | express.urlencoded() |
|—————————–|——————————–|————————————|
| 데이터 형식 | JSON | URL-encoded |
| 주로 사용되는 요청 헤더 | Content-Type: application/json | Content-Type: application/x-www-form-urlencoded |
| 데이터 예시 | { "name": "John" } | name=John&age=30 |
7. 왜 사용해야 하나?
- HTML 폼 데이터를 간단히 처리할 수 있음.
- Express에서 요청 본문을 읽고 구조화하는 작업을 자동화.
- RESTful API에서 클라이언트와 서버 간의 데이터 교환을 쉽게 처리 가능.
결론
app.use(express.urlencoded({ extended: true }));는:
- HTML 폼 데이터를 파싱하여
req.body에 저장하는 데 사용. extended: true로 설정하면 복잡한 데이터 구조(중첩 객체, 배열)도 처리 가능.- 폼 데이터를 처리하는 모든 Express 애플리케이션에서 필수적으로 사용됩니다.
next는 Express에서 미들웨어 체인을 이어주는 역할을 하는 함수입니다.
미들웨어에서 next()를 호출하면 다음 미들웨어로 제어가 넘어갑니다. 만약 next()를 호출하지 않으면, 요청 처리가 그 지점에서 멈추게 됩니다.
next()
1. next의 역할
- 요청 흐름을 다음 미들웨어로 전달:
- 요청이 처리되는 동안 여러 미들웨어를 순차적으로 실행할 수 있습니다.
- 현재 미들웨어가 작업을 완료한 후,
next()를 호출하여 제어를 다음 미들웨어로 넘깁니다.
- 응답 종료:
- 특정 미들웨어에서 요청을 완전히 처리할 수 있다면,
next()를 호출하지 않고 응답을 종료합니다.
- 특정 미들웨어에서 요청을 완전히 처리할 수 있다면,
2. 미들웨어의 구조
미들웨어는 요청(Request), 응답(Response), 그리고 다음 작업(Next)을 처리할 수 있는 함수입니다.
function middleware(req, res, next) {
// 요청 처리 작업
next(); // 다음 미들웨어로 이동
}
3. next()의 동작 방식
- 요청 흐름: 미들웨어는 등록된 순서대로 실행됩니다.
next()를 호출하면 Express는 다음으로 등록된 미들웨어를 실행합니다.- 마지막으로, 라우터 핸들러가 실행됩니다.
4. 예제 코드
예제: 여러 미들웨어 연결
const express = require("express");
const app = express();
app.use((req, res, next) => {
console.log("Middleware 1");
next(); // 다음 미들웨어로 넘어감
});
app.use((req, res, next) => {
console.log("Middleware 2");
next(); // 다음 미들웨어로 넘어감
});
app.get("/", (req, res) => {
console.log("Route Handler");
res.send("Hello, World!");
});
app.listen(3000, () => console.log("Server running on port 3000"));
출력:
Middleware 1
Middleware 2
Route Handler
예제: next()를 호출하지 않는 경우
app.use((req, res, next) => {
console.log("Middleware 1");
// next()를 호출하지 않음
res.send("Stopped here");
});
app.use((req, res, next) => {
console.log("Middleware 2");
next();
});
app.get("/", (req, res) => {
console.log("Route Handler");
res.send("Hello, World!");
});
출력:
Middleware 1
next()가 호출되지 않으면 “Middleware 1”에서 요청 처리가 종료되고, 이후의 미들웨어나 라우터는 실행되지 않습니다.
5. 중요한 사용 사례
요청 전처리
- 예를 들어, 모든 요청에 대해 인증을 수행하려면 미들웨어를 사용합니다.
app.use((req, res, next) => { console.log("Checking authentication..."); // 인증 로직 next(); });
응답 데이터 수정
- 요청 처리 전에 데이터나 응답을 미리 가공하거나 추가 작업을 수행할 수 있습니다.
```javascript
app.use((req, res, next) => {
req.customData = “Hello, Middleware!”;
next();
});
app.get(“/”, (req, res) => {
res.send(req.customData); // “Hello, Middleware!”
});
#### 에러 처리
- `next`에 에러 객체를 전달하면 Express의 에러 핸들링 미들웨어로 이동합니다.
```javascript
app.use((req, res, next) => {
const error = new Error("Something went wrong");
next(error); // 에러 핸들러로 이동
});
app.use((err, req, res, next) => {
console.error(err.message);
res.status(500).send("Internal Server Error");
});
6. next를 호출하지 않는 경우
- 미들웨어가 요청을 완전히 처리한 경우,
next()를 호출하지 않아도 됩니다. - 예: 요청을 처리하고 응답을 반환하는 경우.
app.use((req, res) => { res.send("Request handled here"); // next()를 호출하지 않아도 됨 });
7. 결론
next()는 Express에서 미들웨어 체인을 이어주는 함수로, 요청을 다음 미들웨어 또는 라우터로 전달합니다.- 호출하지 않으면 요청 처리가 멈추므로, 응답을 끝내지 않을 경우 반드시 호출해야 합니다.
next()를 통해 전처리, 로깅, 인증, 에러 처리 등 다양한 작업을 체계적으로 구성할 수 있습니다.
Query Parameter
Query Parameter는 HTTP 요청의 URL에서 데이터를 전달하는 방식 중 하나입니다. 클라이언트가 서버로 요청할 때 “키-값 쌍” 형태로 데이터를 URL에 포함하여 보낼 수 있습니다.
1. Query Parameter의 위치
- Query Parameter는 URL에서
?뒤에 나타납니다. - 각 쿼리 매개변수는 키=값의 형태로 작성되며, 여러 매개변수는
&로 구분됩니다.
예:
https://example.com/search?query=express&sort=asc&page=2
?query=express: 쿼리 문자열 시작.&sort=asc: 두 번째 매개변수.&page=2: 세 번째 매개변수.
2. Query Parameter의 특징
- 서버에 요청 데이터를 전달하는 데 사용됩니다.
- GET 요청과 함께 자주 사용되며, URL에 포함되기 때문에 가시적입니다.
- 데이터를 간단히 전달하는 데 적합하며, 보안이 중요하지 않은 경우 사용됩니다.
3. Express에서 Query Parameter 사용
Express에서는 request.query 객체를 통해 Query Parameter에 접근할 수 있습니다.
예제 코드:
const express = require("express");
const app = express();
app.get("/search", (req, res) => {
console.log(req.query);
res.send(req.query);
});
app.listen(3000, () => {
console.log("Server is running on port 3000");
});
클라이언트 요청:
GET /search?query=express&sort=asc&page=2
서버 출력:
{
query: "express",
sort: "asc",
page: "2"
}
4. Query Parameter의 활용 예
a) 검색 요청
app.get("/search", (req, res) => {
const { query, sort, page } = req.query;
console.log(`Searching for: ${query}, Sort: ${sort}, Page: ${page}`);
res.send("Search results");
});
요청:
GET /search?query=express&sort=desc&page=1
서버 응답:
Searching for: express, Sort: desc, Page: 1
b) 필터링 및 정렬
app.get("/products", (req, res) => {
const { category, minPrice, maxPrice } = req.query;
res.send(`Filter by: ${category}, Price between ${minPrice} and ${maxPrice}`);
});
요청:
GET /products?category=electronics&minPrice=100&maxPrice=500
서버 응답:
Filter by: electronics, Price between 100 and 500
5. Query Parameter와 Route Parameter 비교
| 특징 | Query Parameter | Route Parameter |
|---|---|---|
| 위치 | URL의 ? 뒤에 key=value 형태로 추가 |
URL 경로의 일부 (/path/:id) |
| 형식 | ?key1=value1&key2=value2 |
/resource/:id |
| 사용 용도 | 데이터 필터링, 검색, 옵션 전달 | 특정 리소스를 식별 |
| Express에서 접근 방식 | req.query |
req.params |
| 예 | /search?query=express&page=1 |
/user/123 |
6. 유효성 검사 및 기본값 처리
유효성 검사:
Query Parameter는 클라이언트가 직접 작성하므로, 잘못된 값이 전달될 수 있습니다. 이를 방지하려면 유효성 검사를 추가해야 합니다.
app.get("/search", (req, res) => {
const { query, page } = req.query;
if (!query) {
return res.status(400).send({ error: "Query is required" });
}
if (page && isNaN(page)) {
return res.status(400).send({ error: "Page must be a number" });
}
res.send(`Search results for: ${query}`);
});
기본값 처리:
클라이언트가 값을 제공하지 않은 경우, 기본값을 설정할 수 있습니다.
app.get("/search", (req, res) => {
const query = req.query.query || "default";
const page = req.query.page || 1;
res.send(`Searching for: ${query}, Page: ${page}`);
});
7. Query Parameter의 한계
- 데이터가 URL에 포함되므로 민감한 정보(비밀번호 등)를 전달하기에는 적합하지 않습니다.
- URL 길이에 제한이 있기 때문에, 대량의 데이터를 전달할 수 없습니다.
8. 결론
Query Parameter는 가볍고 간단한 데이터 전달을 위해 사용됩니다. 검색, 필터링, 페이지네이션 등 클라이언트가 서버에 옵션을 전달할 때 적합하며, Express에서는 req.query를 통해 쉽게 접근하고 처리할 수 있습니다.
AWS
계정보안
- 보안강화를 위해서 MFA 설정
- 그룹 생성시 관리자 권한을 위해
Administrator Access옵션 포함 - 유저 생성시
Provide user access to the AWS Management Console > I want to create an IAM user체크 - 유저에게 권한을 줄 경우
Attach policies directly체크 ->Administrator Access옵션 선택
VPC, EC2, RDS
AWS에서 VPC, EC2, RDS는 각각 네트워킹, 컴퓨팅, 데이터베이스 서비스와 관련된 핵심 구성 요소로, 클라우드 인프라를 구축하고 관리하는 데 사용됩니다. 각 서비스를 하나씩 자세히 알아보겠습니다.
1. VPC (Virtual Private Cloud)
VPC란?
VPC는 AWS에서 제공하는 가상 네트워크 환경으로, 클라우드 리소스를 격리된 네트워크 안에서 배치하고 관리할 수 있도록 합니다.
VPC는 사용자가 원하는 대로 네트워크를 설계할 수 있는 가상 데이터센터 역할을 합니다.
주요 기능
- IP 주소 범위 정의:
- VPC 생성 시 CIDR 블록을 설정하여 사용할 IP 주소 범위를 지정.
- 예:
10.0.0.0/16(65,536개의 IP 주소 제공).
- 서브넷(Subnet):
- VPC 내에서 IP 주소 범위를 더 작은 네트워크로 나눔.
- Public Subnet: 인터넷 게이트웨이로 연결되어 외부와 통신 가능.
- Private Subnet: 인터넷과 분리되어 내부 네트워크용으로 사용.
- 라우팅 테이블:
- 네트워크 트래픽의 경로를 정의.
- Public Subnet은 인터넷 게이트웨이(Internet Gateway)를 통해 트래픽을 전달.
- 보안 그룹(SG)과 네트워크 ACL:
- 보안 그룹: 리소스 단위로 인바운드/아웃바운드 트래픽 제어.
- 네트워크 ACL: 서브넷 수준에서 네트워크 트래픽 제어.
- 인터넷 게이트웨이(IGW) 및 NAT 게이트웨이:
- IGW: 퍼블릭 서브넷에서 인터넷과 통신 가능.
- NAT 게이트웨이: 프라이빗 서브넷 리소스가 인터넷에 접근하도록 지원.
VPC 사용 예
- EC2 인스턴스를 퍼블릭 서브넷에 배치하여 인터넷에서 접근 가능한 웹 서버 실행.
- 데이터베이스(RDS)를 프라이빗 서브넷에 배치하여 보안 강화.
2. EC2 (Elastic Compute Cloud)
EC2란?
EC2는 AWS에서 제공하는 가상 서버로, 사용자가 필요에 따라 컴퓨팅 리소스를 프로비저닝하고 관리할 수 있게 합니다.
주요 특징
- 다양한 인스턴스 유형:
- General Purpose: 범용 용도, 예:
t3.micro,m5.large. - Compute Optimized: 고성능 CPU 용도, 예:
c5.large. - Memory Optimized: 대용량 메모리 용도, 예:
r5.large. - Storage Optimized: 고속/대용량 스토리지 용도, 예:
i3.large.
- General Purpose: 범용 용도, 예:
- 온디맨드 및 스팟 인스턴스:
- 온디맨드: 필요할 때만 사용하고 시간당 비용 지불.
- 스팟: 미사용 컴퓨팅 리소스를 저렴하게 사용.
- 가용 영역(AZ) 및 리전:
- 리전 내의 여러 가용 영역(AZ)에 인스턴스를 배치하여 고가용성 제공.
- 키 페어(Key Pair):
- SSH를 사용하여 EC2 인스턴스에 안전하게 연결.
- EBS (Elastic Block Store):
- EC2 인스턴스에 연결할 수 있는 지속 가능한 스토리지.
- Auto Scaling:
- 트래픽에 따라 EC2 인스턴스 수를 자동으로 증가 또는 감소.
EC2 사용 예
- 웹 애플리케이션 서버를 실행하여 HTTP 요청 처리.
- 백엔드 서비스용 API 서버 배포.
- 데이터 분석을 위한 고성능 컴퓨팅 환경 구성.
3. RDS (Relational Database Service)
RDS란?
RDS는 AWS에서 제공하는 관리형 관계형 데이터베이스 서비스입니다.
사용자는 데이터베이스 관리 작업(백업, 복제, 패치)을 자동화하여 데이터베이스 운영 부담을 줄일 수 있습니다.
주요 특징
- 다양한 데이터베이스 엔진 지원:
- Amazon Aurora
- MySQL
- PostgreSQL
- MariaDB
- Oracle
- Microsoft SQL Server
- 자동화된 관리:
- 자동 백업, 소프트웨어 업데이트, 보안 패치.
- 다중 AZ 배포:
- 고가용성을 위해 다른 가용 영역에 데이터베이스 복제본 생성.
- 리드 복제본(Read Replica):
- 읽기 요청을 분산 처리하여 데이터베이스 성능 향상.
- 보안:
- VPC와 통합하여 데이터베이스를 프라이빗 네트워크에서 보호.
- 데이터 암호화(AWS KMS를 사용한 저장 및 전송 암호화).
- 스케일링:
- 필요에 따라 데이터베이스 스토리지와 성능을 수직 확장.
RDS 사용 예
- 웹 애플리케이션의 백엔드 데이터베이스.
- 데이터 분석을 위한 대규모 관계형 데이터베이스.
- 전자 상거래 플랫폼의 주문 및 고객 데이터 관리.
VPC, EC2, RDS 간의 관계
기본적인 클라우드 아키텍처 예
- VPC:
- 네트워크 인프라를 제공.
- 퍼블릭 서브넷에는 인터넷에서 접근 가능한 EC2를 배치.
- 프라이빗 서브넷에는 데이터베이스(RDS)를 배치하여 외부 접근 차단.
- EC2:
- 웹 서버 또는 애플리케이션 서버로 동작.
- 퍼블릭 서브넷에 배치되어 인터넷에서 요청을 수신.
- RDS:
- 프라이빗 서브넷에 배치되어 EC2에서만 접근 가능.
- EC2 애플리케이션이 데이터베이스 작업을 수행.
예제 다이어그램
VPC
├── Public Subnet
│ └── EC2 (웹 서버)
│ └── 인터넷 게이트웨이 연결
├── Private Subnet
└── RDS (데이터베이스)
결론
- VPC: 네트워크 환경을 제공.
- EC2: 애플리케이션 실행을 위한 컴퓨팅 리소스.
- RDS: 데이터 저장 및 관리용 관계형 데이터베이스.
이 세 가지를 조합하여 AWS에서 확장 가능하고 안전한 클라우드 기반 애플리케이션을 구축할 수 있습니다.
VSC 설정
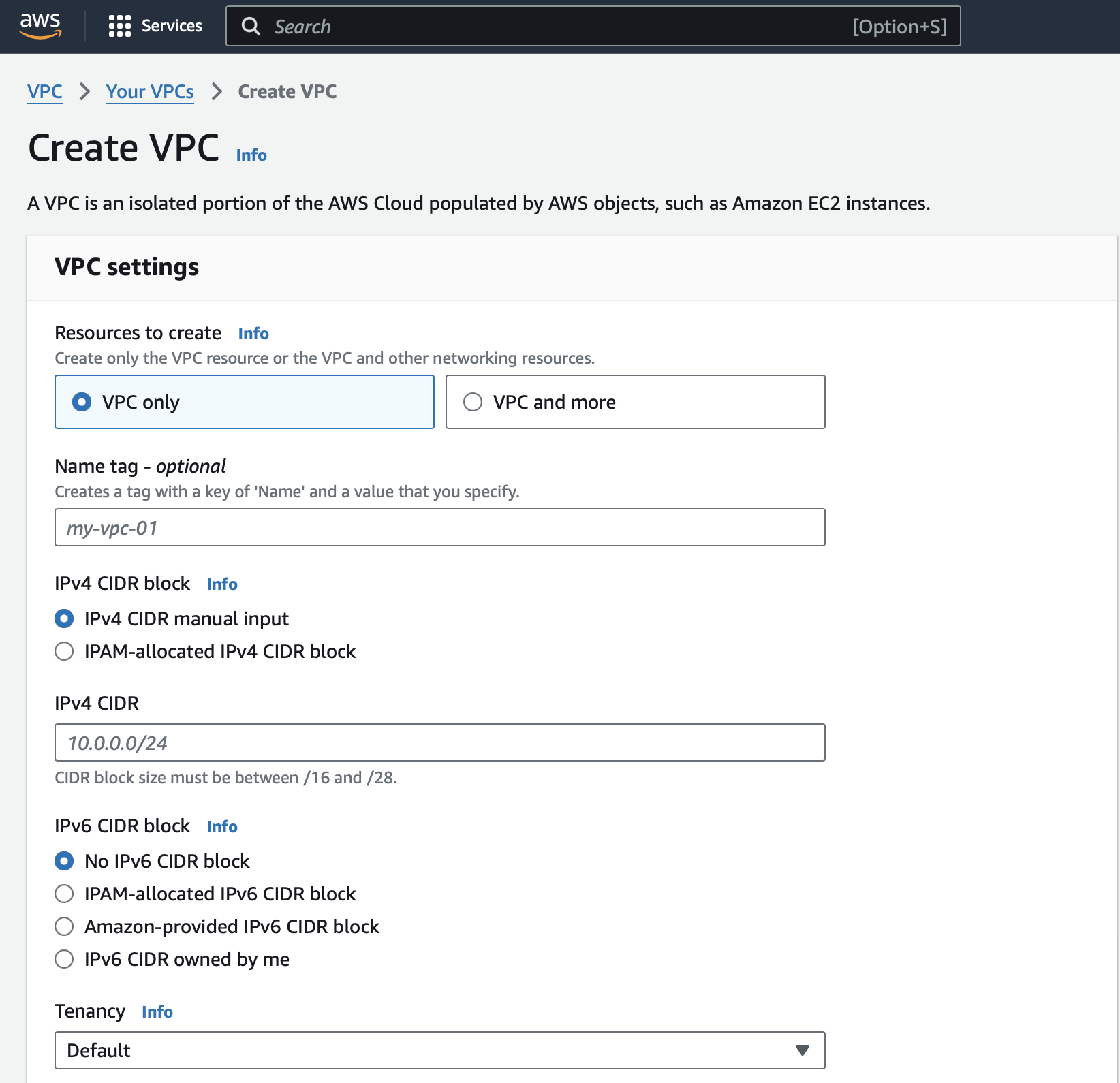
- Create VPC -> VPC and more -> 이름작성 -> create
- 삭제시 DHCP option sets에 가서도 따로 삭제를 해 줘야 함
EC2 설정
- Launch instance -> 이름 작성 -> ubuntu 선택 -> Instance type선택 -> Create key pair 생성 -> Network setting -> vpc선택, subnet public선택 -> Auto-assign public IP에서 Enable -> 생성
EC2 Node 설치
https://docs.aws.amazon.com/ko_kr/sdk-for-javascript/v2/developer-guide/setting-up-node-on-ec2-instance.html
- Connect ->
sudo apt update
sudo apt install curl
(아래부터 사이트 참조)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
source ~/.bashrc
nvm install --lts
node -e "console.log('Running Node.js ' + process.version)"
EC2 Express 설치
npx express-generator test (test는 폴더이름)
cd test
npm install
npm start
- Instances -> 하단에 Security -> Inbound rules -> Security group ID체크 -> 하단에 뜨는 탭 중에 Inbound rules -> Edit inbound rules
-
3가지 추가
Type : Custom TCP / Port range : 3000 / Source type : Anywhere-IPv4
Type : HTTP / Source type : Anywhere-IPv4
Type : HTTPS/ Source type : Anywhere-IPv4 - http://13.125.156.63:3000/ (http, 3000 주소에 붙여주고 화면 띄워서 확인)
AWS EC2 Express 정리
- 매번 npm start해서 코드 수정하는 게 번거롭기 때문에 Git을 활용 (git clone)
- ✅ CICD 기술로 깃허브에 푸쉬를 하면 자동으로 빌드를 해서 코드를 옮기고 서버가 재동작하는 방식으로 하는 게 일반적이다
EC2 삭제
Instance state -> Terminate instance, key나 보이는 것들 수동으로 삭제
AWS AuroraDB
Amazon Aurora는 AWS에서 제공하는 고성능, 고가용성 관계형 데이터베이스 서비스로, MySQL 및 PostgreSQL과 호환됩니다. Aurora는 AWS의 RDS(Relational Database Service) 제품군의 일부로, 대규모 클라우드 애플리케이션에서 요구되는 확장성과 안정성을 제공하면서도 비용 효율적인 관리형 데이터베이스 솔루션입니다.
1. Aurora의 특징
1) MySQL 및 PostgreSQL 호환
- Aurora는 MySQL 및 PostgreSQL과 완벽히 호환되어 기존 애플리케이션과 쉽게 통합 가능합니다.
- Aurora MySQL은 최대 5배 빠름, Aurora PostgreSQL은 최대 3배 빠름으로 설계되었습니다.
2) 고성능
- SSD 기반의 데이터 스토리지로 읽기 및 쓰기 작업의 지연 시간이 낮음.
- 데이터베이스 클러스터 내에서 읽기 복제본(Read Replicas)을 활용해 읽기 작업 성능을 확장 가능.
3) 고가용성 및 복구
- 다중 AZ(가용 영역) 배포:
- 데이터를 6개의 복사본으로 분산(3개의 AZ에 각 2개씩) 저장하여 데이터 손실을 방지.
- 데이터 손상이 발생하면 자동으로 복구.
- 자동 백업:
- 지속적인 백업과 특정 시점 복구(Point-In-Time Recovery) 지원.
- 자동 장애 조치(Failover):
- 클러스터의 기본 데이터베이스가 실패하면 읽기 복제본이 즉시 승격되어 서비스 중단 최소화.
4) 확장성
- 스토리지 확장:
- 데이터베이스 크기를 사전에 설정할 필요 없이 자동으로 확장(최대 128TB).
- 읽기 복제본:
- 최대 15개의 읽기 복제본을 생성하여 읽기 작업을 분산.
5) 보안
- 네트워크 보안:
- Amazon VPC와 통합하여 데이터베이스를 네트워크적으로 격리 가능.
- 데이터 암호화:
- 저장 데이터와 전송 중인 데이터를 AWS KMS(Key Management Service)로 암호화.
- IAM 통합:
- AWS IAM(Identity and Access Management)을 통해 인증 및 권한 제어.
6) 비용 효율성
- Aurora는 고성능을 제공하면서도 상용 데이터베이스(예: Oracle, Microsoft SQL Server) 대비 비용이 1/10 수준.
2. Aurora의 구성 요소
1) Aurora 클러스터
- Aurora 데이터베이스는 하나의 클러스터로 구성되며, 클러스터에는 다음이 포함됩니다:
- 기본 인스턴스(Primary Instance):
- 쓰기 작업을 처리.
- 읽기 복제본(Read Replica):
- 읽기 전용 요청을 처리하여 성능 확장.
- 기본 인스턴스(Primary Instance):
2) Aurora 스토리지 계층
- 분산된 다중 AZ에 걸쳐 스토리지 자동 확장.
- 스토리지는 쓰기 작업의 크기에 따라 자동으로 확장(최대 128TB).
3) Amazon Aurora Serverless
- 온디맨드 자동 스케일링 기능을 제공하며, 트래픽 변동이 심한 애플리케이션에 적합.
- 애플리케이션 요청에 따라 컴퓨팅 용량을 자동으로 증가 또는 감소.
3. Aurora의 사용 사례
1) 웹 애플리케이션 데이터베이스
- 고성능 및 확장성이 필요한 애플리케이션.
- 예: 전자 상거래 플랫폼, 블로그 시스템.
2) 데이터 분석
- 대량의 읽기 작업을 처리하고 읽기 복제본을 활용하여 분석 쿼리의 성능을 향상.
3) IoT 애플리케이션
- IoT 디바이스에서 생성된 데이터를 Aurora에 저장하고, 빠른 읽기/쓰기 작업 처리.
4) 멀티 테넌트 SaaS 애플리케이션
- 여러 고객 데이터를 처리하는 멀티 테넌트 애플리케이션에 적합.
4. Aurora vs 다른 데이터베이스
| 특징 | Aurora | MySQL/PostgreSQL | Oracle / SQL Server |
|---|---|---|---|
| 호환성 | MySQL, PostgreSQL | 해당 DB 자체 | 고유 포맷 |
| 성능 | MySQL 대비 최대 5배 빠름 | 기본 성능 | 높은 성능 |
| 스토리지 확장 | 자동 확장(최대 128TB) | 제한적 | 제한적 |
| 읽기 복제본 | 최대 15개 지원 | 5개 제한 | 제한적 |
| 고가용성 및 복구 | 다중 AZ 및 자동 복구 | 제한적 | 고급 복구 지원 |
| 비용 | 비용 효율적 | 저렴 | 고비용 |
5. Aurora의 구성 예시
아키텍처
VPC
├── Public Subnet
│ └── EC2 인스턴스 (웹 서버)
├── Private Subnet
├── Aurora Primary Instance (쓰기 전용)
└── Aurora Read Replica (읽기 전용)
- EC2 웹 서버: Public Subnet에 배치, 인터넷과 통신.
- Aurora Primary Instance: Private Subnet에 배치, 쓰기 작업 처리.
- Aurora Read Replica: 읽기 작업을 분산 처리하여 성능 향상.
6. Aurora의 주요 장점
- 고성능: MySQL/PostgreSQL 대비 3~5배 빠른 성능.
- 고가용성: 다중 AZ에 데이터 복제 및 자동 장애 조치.
- 확장성: 데이터 크기에 따라 스토리지 자동 확장.
- 관리 자동화: 백업, 복구, 패치 등이 자동화되어 관리 부담 감소.
- 비용 효율성: 상용 데이터베이스 대비 낮은 비용.
Amazon Aurora는 AWS에서 대규모 애플리케이션 및 고성능 데이터베이스가 필요한 환경에서 가장 적합한 선택입니다. 특히, MySQL이나 PostgreSQL과 호환되기 때문에 기존 데이터베이스를 Aurora로 쉽게 마이그레이션할 수 있습니다.
AWS RDS subnet 설정
- RDS -> Subnet groups -> Create DB subnet group 에서 VPC에 맞춰서 설정
AWS RDS 설정 - public
Create database -> MySQL -> Templates : Free tier
Storage autoscaling 체크
생성한 VPC, subnet group 선택
강의는 EC2없이 public으로 생성했기 때문에 Public access Yes체크
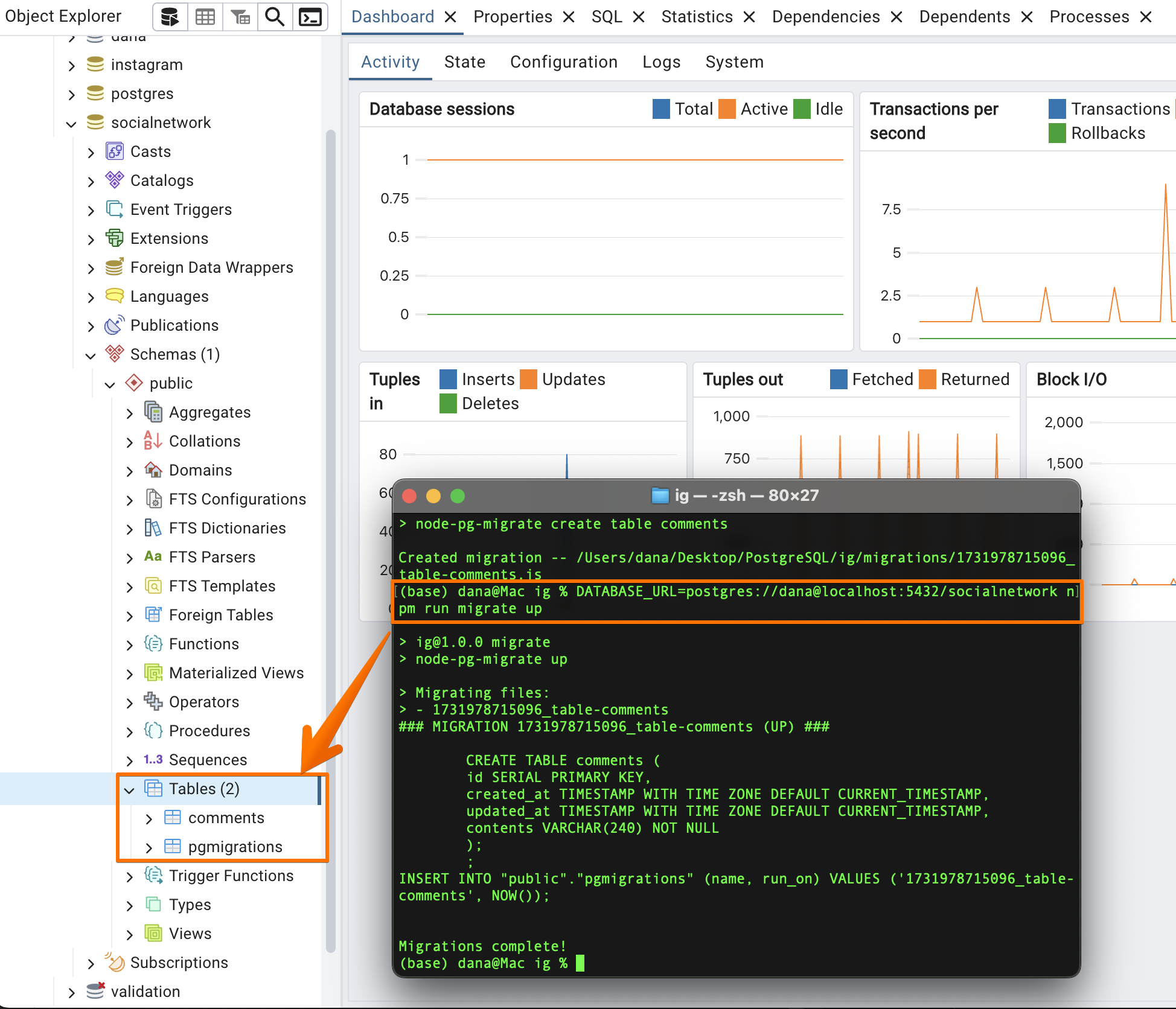 Transaction and Migration
Transaction and Migration