Working with Tables
-
Primary Key : 테이블의 각 행을 고유하게 식별하는 컬럼(또는 컬럼의 조합)
기본 키는 중복될 수 없고 NULL 값을 가질 수 없다.
Primary Key를 설정하면 데이터베이스는 자동으로 인덱스를 생성하여 검색 성능을 향상시킨다. -
Foreign Key : 한 테이블의 컬럼이 다른 테이블의 Primary Key 또는 Unique Key를 참조하도록 설정된 키
-
SERIAL: 자동 증가하는 정수형 컬럼을 생성하기 위한 데이터 타입
데이터가 삽입될 때마다 자동으로 1씩 증가하는 고유 값을 할당받는다.
PostgreSQL에서는 저장할 수 있는 값의 크기에 따라 SERIAL, SMALLSERIAL, BIGSERIAL을 제공한다.- SERIAL : 일반적인 정수형(INTEGER) 시퀀스로, 32비트 범위 (-2,147,483,648 ~ 2,147,483,647) 내에서 사용
- SMALLSERIAL : 작은 정수형(SMALLINT) 시퀀스로, 16비트 범위 (-32,768 ~ 32,767) 내에서 사용
- BIGSERIAL : 큰 정수형(BIGINT) 시퀀스로, 64비트 범위 (-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807) 내에서 사용
Creating Foreign Key Columns
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
employee_id INTEGER,
FOREIGN KEY (employee_id) REFERENCES employees(employee_id) );
JOIN: 여러 테이블을 연결하여 하나의 결과 집합으로 만드는 데 사용되는 키워드
데이터베이스에서는 여러 테이블에 걸쳐 데이터를 나누어 저장하는 경우가 많기 때문에, 이 데이터를 조합하여 필요한 정보를 얻기 위해 JOIN을 사용
✅ JOIN 만 썼을 경우 INNER JOIN으로 인식
JOIN은 SQL에서 여러 테이블을 연결하여 하나의 결과 집합으로 만드는 데 사용되는 키워드입니다. 데이터베이스에서는 여러 테이블에 걸쳐 데이터를 나누어 저장하는 경우가 많기 때문에, 이 데이터를 조합하여 필요한 정보를 얻기 위해 JOIN을 사용합니다.
- LEFT JOIN: FROM 뒤에 나오는 첫 번째 테이블이 기준.
- RIGHT JOIN: JOIN 뒤에 나오는 두 번째 테이블이 기준.
JOIN의 종류
JOIN은 주로 다음과 같은 종류가 있습니다:
- INNER JOIN:
- 두 테이블에서 조건을 만족하는 공통된 데이터만 가져옵니다.
- 두 테이블 간 일치하는 값이 있을 때만 결과에 포함됩니다.
- 예를 들어,
employees와departments테이블을INNER JOIN으로 조인할 때, 두 테이블 모두에서 일치하는department_id가 있는 행만 결과에 포함됩니다.
SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id; - LEFT JOIN (또는 LEFT OUTER JOIN):
- 왼쪽(첫 번째) 테이블의 모든 행을 가져오고, 오른쪽 테이블에서 일치하는 값이 있으면 해당 값을 가져옵니다.
- 오른쪽 테이블에 일치하는 값이 없는 경우
NULL로 표시됩니다. - 예를 들어,
employees테이블에 있는 모든 직원 정보를 포함하고, 해당 직원의 부서 정보가 없는 경우NULL이 반환됩니다.
SELECT employees.name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id; - RIGHT JOIN (또는 RIGHT OUTER JOIN):
- 오른쪽(두 번째) 테이블의 모든 행을 가져오고, 왼쪽 테이블에서 일치하는 값이 있으면 해당 값을 가져옵니다.
- 왼쪽 테이블에 일치하는 값이 없는 경우
NULL로 표시됩니다. - 예를 들어,
departments테이블에 있는 모든 부서 정보를 포함하고, 해당 부서에 직원이 없는 경우 직원 정보가NULL로 표시됩니다.
SELECT employees.name, departments.department_name FROM employees RIGHT JOIN departments ON employees.department_id = departments.department_id; - FULL JOIN (또는 FULL OUTER JOIN):
- 두 테이블의 모든 행을 가져옵니다, 일치하는 데이터가 있는 경우에는 함께 결합하고, 일치하지 않는 경우
NULL로 표시됩니다. - 결과적으로 양쪽 테이블에 일치하는 값이 없더라도 모든 데이터를 포함합니다.
SELECT employees.name, departments.department_name FROM employees FULL JOIN departments ON employees.department_id = departments.department_id; - 두 테이블의 모든 행을 가져옵니다, 일치하는 데이터가 있는 경우에는 함께 결합하고, 일치하지 않는 경우
- CROSS JOIN:
- 두 테이블의 모든 조합(카티션 곱)을 생성합니다. 조건이 없으면 두 테이블의 행 수를 곱한 만큼의 결과가 생성됩니다.
- 일반적으로 모든 조합이 필요할 때 사용하며, 대부분의 경우 특정 조건을 사용하지 않으면 데이터 양이 매우 커질 수 있습니다.
SELECT employees.name, departments.department_name FROM employees CROSS JOIN departments; - WHERE와 쓰는 경우
- JOIN을 사용할 때 WHERE 절을 함께 사용하면 두 테이블을 결합한 결과에서 추가적인 조건을 적용하여 데이터를 필터링할 수 있습니다. 이는 JOIN이 수행된 후 특정 조건에 맞는 데이터만 결과로 남기도록 하는 방식입니다.
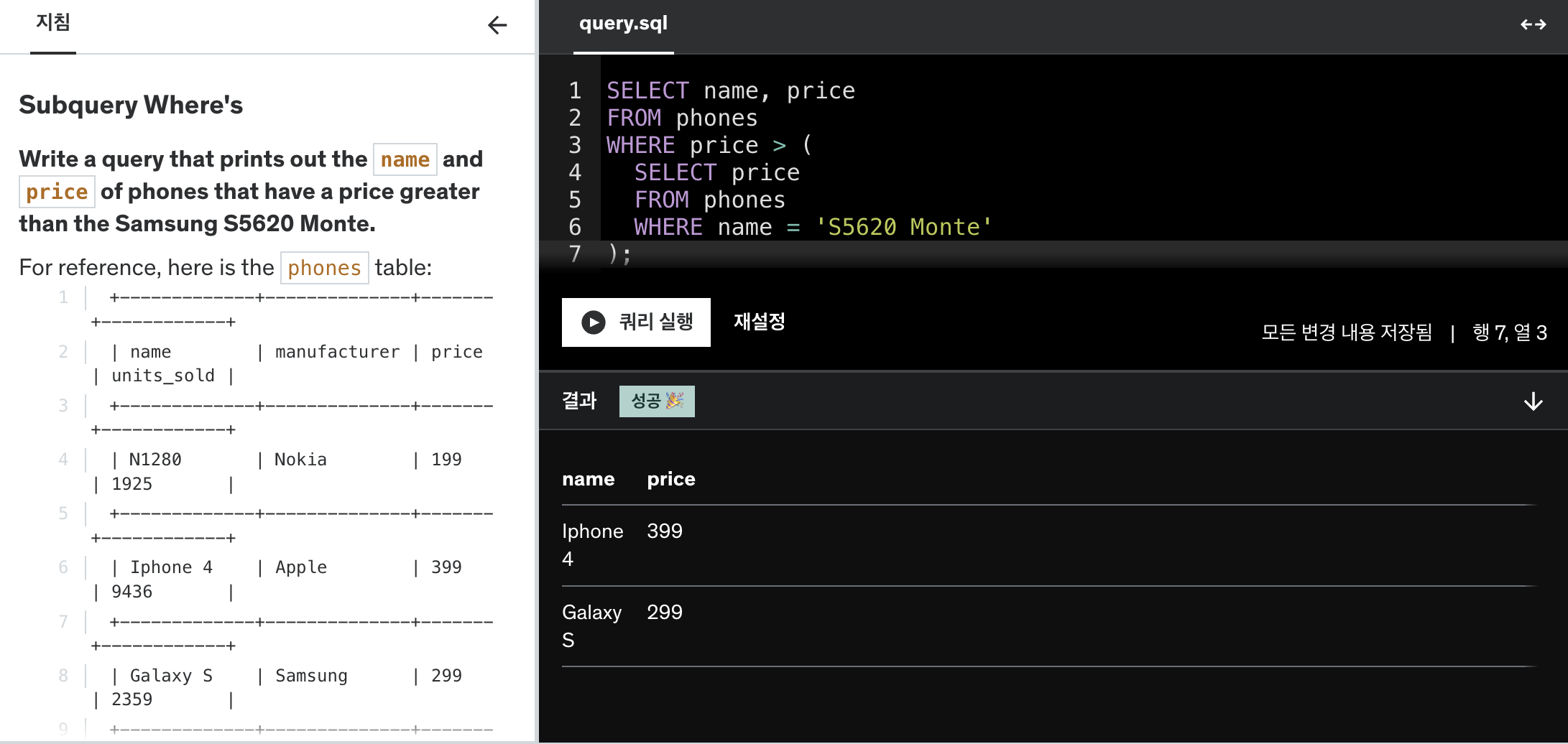
SELECT books.title, authors.name
FROM books
JOIN authors ON books.author_id = authors.id
WHERE authors.name = 'Stephen King';
JOIN 사용의 실제 예시
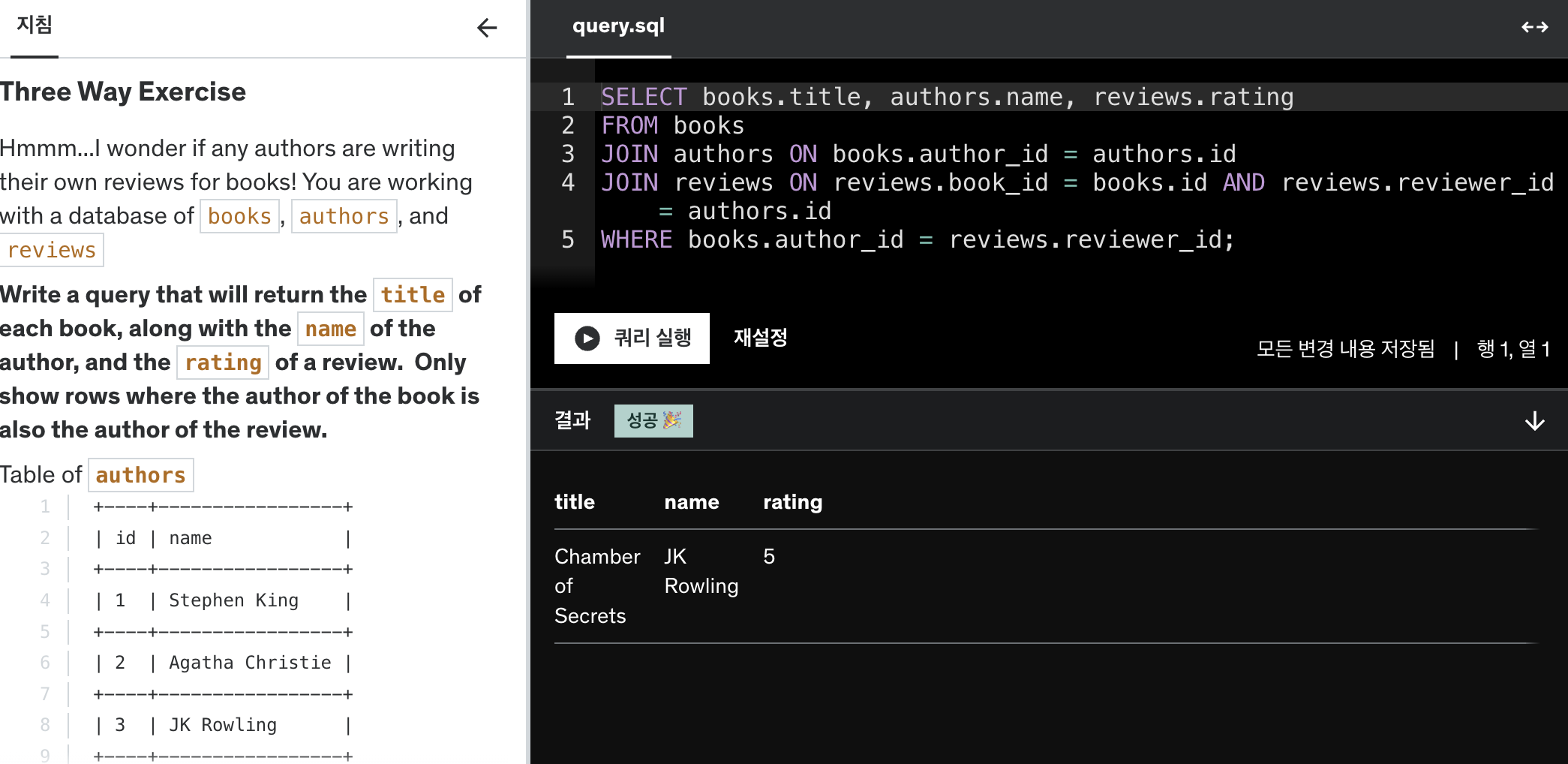
예를 들어, employees 테이블과 departments 테이블이 각각 직원 정보와 부서 정보를 가지고 있다고 가정해봅시다. employees 테이블의 department_id와 departments 테이블의 department_id를 통해 두 테이블을 연결하여 부서와 직원의 정보를 함께 조회할 수 있습니다.
SELECT employees.name, departments.department_name
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id;
이 쿼리는 각 직원의 이름과 해당 부서 이름을 가져옵니다.
JOIN의 장점
- 데이터 통합: 여러 테이블에 저장된 데이터를 효율적으로 통합하여 원하는 정보를 한 번에 가져올 수 있습니다.
- 데이터 무결성 유지: 외래 키를 통해 테이블 간 관계를 정의하고
JOIN을 활용하면 데이터 무결성을 보장하면서 데이터를 조회할 수 있습니다.
JOIN은 관계형 데이터베이스에서 여러 테이블의 데이터를 연결하고, 원하는 데이터를 조회하는 데 핵심적인 역할을 합니다.
Constraints Around Deletion
ON DELETE 옵션은 외래 키(Foreign Key) 제약 조건에서 부모 테이블의 행이 삭제될 때 자식 테이블에 어떤 영향을 미칠지 설정하는 옵션입니다. PostgreSQL을 포함한 여러 데이터베이스 시스템에서 지원하는 이 옵션들을 하나씩 설명드리겠습니다.
1. ON DELETE RESTRICT
- 부모 테이블의 행이 자식 테이블에서 참조 중인 경우 삭제가 제한됩니다.
- 자식 테이블에서 해당 외래 키 값이 있는 한 부모 테이블의 행을 삭제할 수 없습니다.
- 참조 무결성을 강하게 유지하며, 데이터 삭제 시 의도하지 않은 연쇄 삭제를 방지할 수 있습니다.
FOREIGN KEY (column_name) REFERENCES parent_table(column_name) ON DELETE RESTRICT;
2. ON DELETE NO ACTION
RESTRICT와 유사하게 부모 테이블의 행을 삭제할 때 자식 테이블에서 참조 중인 행이 있으면 에러가 발생합니다.- 즉시 삭제가 제한되며, 데이터 삭제 시 참조 무결성을 유지하려는 목적이 동일합니다.
NO ACTION과RESTRICT는 대부분의 경우 같은 방식으로 동작합니다.
FOREIGN KEY (column_name) REFERENCES parent_table(column_name) ON DELETE NO ACTION;
3. ON DELETE CASCADE
- 부모 테이블의 행이 삭제될 때, 이를 참조하는 자식 테이블의 행도 자동으로 삭제됩니다.
- 부모-자식 관계에서 부모 데이터가 사라질 때 자식 데이터도 함께 삭제되는 연쇄 삭제가 필요할 때 유용합니다.
- 예를 들어, 주문을 삭제하면 해당 주문의 모든 주문 항목도 삭제되도록 할 수 있습니다.
FOREIGN KEY (column_name) REFERENCES parent_table(column_name) ON DELETE CASCADE;
4. ON DELETE SET NULL
- 부모 테이블의 행이 삭제되면 자식 테이블의 해당 외래 키 값이 NULL로 설정됩니다.
- 외래 키가
NULL을 허용할 때만 사용할 수 있으며, 부모 데이터가 삭제되더라도 자식 데이터를 남겨야 할 때 유용합니다. - 예를 들어, 프로젝트 삭제 시 해당 프로젝트의 작업들은 남겨두되, 프로젝트 외래 키 값은
NULL로 변경하도록 할 수 있습니다.
FOREIGN KEY (column_name) REFERENCES parent_table(column_name) ON DELETE SET NULL;
5. ON DELETE SET DEFAULT
- 부모 테이블의 행이 삭제되면 자식 테이블의 외래 키 값이 미리 정의된 기본값(DEFAULT)으로 설정됩니다.
- 외래 키 컬럼에 기본값이 설정되어 있어야 하며, 부모 데이터 삭제 후 자식 데이터를 기본값으로 유지해야 할 때 사용합니다.
FOREIGN KEY (column_name) REFERENCES parent_table(column_name) ON DELETE SET DEFAULT;
요약
- RESTRICT / NO ACTION: 부모 테이블의 데이터가 자식 테이블에서 참조될 때 삭제 제한.
- CASCADE: 부모 테이블의 데이터가 삭제되면 자식 테이블의 참조 데이터도 함께 삭제.
- SET NULL: 부모 데이터가 삭제되면 자식 테이블의 외래 키 값이
NULL로 설정. - SET DEFAULT: 부모 데이터가 삭제되면 자식 테이블의 외래 키 값이 기본값으로 설정.
이 옵션들은 데이터 무결성을 유지하면서 데이터베이스 내에서 논리적인 참조 관계를 관리하는 데 도움을 줍니다.
 SQL Statements
SQL Statements