Aggregation of Records
GROUP BY는 SQL에서 데이터를 그룹화하여 요약 정보를 계산할 때 사용하는 절입니다. 여러 행을 특정 기준에 따라 그룹으로 묶고, 그룹별로 집계 함수(예: COUNT, SUM, AVG, MAX, MIN)를 적용할 수 있습니다.
GROUP BY의 기본 구조
SELECT 컬럼명1, 컬럼명2, 집계함수
FROM 테이블명
GROUP BY 컬럼명1, 컬럼명2;
GROUP BY는SELECT구문에서 지정된 특정 컬럼을 기준으로 데이터를 그룹화합니다.- 그룹화된 각 그룹에 대해 하나의 결과 행이 반환됩니다.
- 주로
COUNT,SUM,AVG와 같은 집계 함수와 함께 사용됩니다.
예시 테이블
예를 들어, sales라는 테이블이 있고 각 판매 내역이 다음과 같이 저장되어 있다고 가정합니다.
| id | product | category | amount |
|---|---|---|---|
| 1 | Laptop | Electronics | 1200 |
| 2 | Phone | Electronics | 800 |
| 3 | T-shirt | Apparel | 20 |
| 4 | Jeans | Apparel | 40 |
| 5 | TV | Electronics | 1500 |
1. 기본적인 GROUP BY 사용
예를 들어, 카테고리별로 판매 건수를 계산하고 싶다면 GROUP BY를 다음과 같이 사용할 수 있습니다.
SELECT category, COUNT(*) AS sales_count
FROM sales
GROUP BY category;
결과:
| category | sales_count |
|————-|————-|
| Electronics | 3 |
| Apparel | 2 |
여기서:
GROUP BY category는category컬럼을 기준으로 데이터를 그룹화합니다.- 각
category별로 행이 하나씩 생성되며,COUNT(*)함수는 각 그룹의 행 개수를 계산합니다.
2. GROUP BY와 SUM 함께 사용하기
카테고리별로 총 판매 금액을 구하려면 SUM 함수를 사용할 수 있습니다.
SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category;
결과:
| category | total_sales |
|————-|————-|
| Electronics | 3500 |
| Apparel | 60 |
여기서:
SUM(amount)는 각category그룹 내의amount값을 합산합니다.
3. 여러 컬럼을 기준으로 그룹화하기
GROUP BY에서는 여러 컬럼을 기준으로 그룹화할 수도 있습니다. 예를 들어, 제품별로 카테고리와 함께 그룹화하여 각 제품의 총 판매 금액을 구할 수 있습니다.
SELECT category, product, SUM(amount) AS total_sales
FROM sales
GROUP BY category, product;
결과:
| category | product | total_sales |
|————-|———|————-|
| Electronics | Laptop | 1200 |
| Electronics | Phone | 800 |
| Apparel | T-shirt | 20 |
| Apparel | Jeans | 40 |
| Electronics | TV | 1500 |
이렇게 하면 category와 product별로 세부적으로 그룹화된 결과를 볼 수 있습니다.
4. HAVING 절과 함께 사용하기
WHERE 절은 GROUP BY 이전에 필터링을 적용하지만, HAVING 절은 GROUP BY 이후의 그룹화된 데이터에 필터를 적용합니다. 예를 들어, total_sales가 1000 이상인 카테고리만 선택하려면 HAVING을 사용합니다.
SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category
HAVING SUM(amount) >= 1000;
결과:
| category | total_sales |
|————-|————-|
| Electronics | 3500 |
여기서:
HAVING SUM(amount) >= 1000조건을 통해 그룹화된 결과 중total_sales가 1000 이상인 카테고리만 출력됩니다.
GROUP BY 요약
- 그룹화 기준:
GROUP BY뒤에 지정한 컬럼(또는 컬럼들)을 기준으로 데이터가 그룹화됩니다. - 집계 함수와 함께 사용: 그룹화된 데이터에
COUNT,SUM,AVG,MAX,MIN등과 같은 집계 함수를 적용할 수 있습니다. - HAVING 절 사용 가능:
HAVING절을 통해 그룹화된 결과에 조건을 걸 수 있습니다.
GROUP BY는 데이터를 집계하고 요약 정보를 도출할 때 매우 유용하며, 복잡한 데이터 분석에 필수적인 SQL 구문입니다.
Sorting Records
ORDER BY는 SQL에서 결과를 정렬할 때 사용하는 절입니다. 쿼리 결과를 오름차순 또는 내림차순으로 정렬하여 출력할 수 있습니다. 기본적으로 SELECT 문과 함께 사용되며, 한 개 또는 여러 개의 컬럼을 기준으로 정렬이 가능합니다.
기본 구조
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
ORDER BY 컬럼명1 [ASC|DESC], 컬럼명2 [ASC|DESC], ...;
ORDER BY뒤에 정렬 기준으로 사용할 컬럼명을 나열합니다.- 각 컬럼 뒤에
ASC(오름차순) 또는DESC(내림차순)을 지정하여 정렬 방향을 설정할 수 있습니다. - 기본 정렬 방향은 오름차순(ASC)입니다.
예시 테이블
employees라는 테이블이 있고, 각 직원의 정보가 다음과 같이 저장되어 있다고 가정합니다.
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | HR | 60000 |
| 2 | Bob | IT | 75000 |
| 3 | Charlie | Sales | 50000 |
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
1. 기본적인 ORDER BY 사용
예를 들어, salary를 기준으로 오름차순으로 정렬하려면 다음과 같이 ORDER BY를 사용합니다.
SELECT name, department, salary
FROM employees
ORDER BY salary;
결과:
| name | department | salary |
|———|————|——–|
| Charlie | Sales | 50000 |
| Edward | Sales | 55000 |
| Alice | HR | 60000 |
| Bob | IT | 75000 |
| Diana | IT | 80000 |
위 쿼리는 salary 컬럼을 기준으로 오름차순(작은 값에서 큰 값 순)으로 정렬합니다.
2. 내림차순 정렬 (DESC)
내림차순으로 정렬하려면 DESC 키워드를 사용합니다. 예를 들어, salary를 기준으로 높은 순서대로 정렬하려면 다음과 같이 작성합니다.
SELECT name, department, salary
FROM employees
ORDER BY salary DESC;
결과:
| name | department | salary |
|———|————|——–|
| Diana | IT | 80000 |
| Bob | IT | 75000 |
| Alice | HR | 60000 |
| Edward | Sales | 55000 |
| Charlie | Sales | 50000 |
이제 salary 컬럼을 기준으로 높은 값에서 낮은 값 순으로 정렬됩니다.
3. 여러 컬럼으로 정렬
ORDER BY에서는 여러 컬럼을 지정하여 정렬할 수 있습니다. 예를 들어, department별로 오름차순 정렬하고, 같은 department 내에서는 salary를 내림차순으로 정렬하려면 다음과 같이 작성할 수 있습니다.
SELECT name, department, salary
FROM employees
ORDER BY department ASC, salary DESC;
결과:
| name | department | salary |
|———|————|——–|
| Alice | HR | 60000 |
| Diana | IT | 80000 |
| Bob | IT | 75000 |
| Edward | Sales | 55000 |
| Charlie | Sales | 50000 |
위 결과에서는 department를 기준으로 오름차순으로 정렬되었고, 같은 부서 내에서는 salary가 내림차순으로 정렬되었습니다.
4. 숫자나 별칭을 사용하여 정렬
ORDER BY에서는 컬럼명을 직접 지정하는 대신, 컬럼의 순서 번호나 별칭을 사용하여 정렬할 수도 있습니다.
-
컬럼 번호:
SELECT절에서 선택된 컬럼의 순서에 따라 정렬이 가능합니다.SELECT name, department, salary FROM employees ORDER BY 3 DESC; -- 세 번째 컬럼(salary) 기준 내림차순 -
별칭: 컬럼에 별칭을 지정해 사용하면 더 직관적입니다.
SELECT name, department, salary AS income FROM employees ORDER BY income DESC;
요약
ORDER BY는 쿼리 결과를 특정 컬럼을 기준으로 정렬할 때 사용합니다.- 기본 정렬 방식은 오름차순(
ASC), 내림차순은DESC를 지정합니다. - 여러 컬럼을 기준으로 다단계 정렬이 가능하며,
SELECT절의 컬럼 번호나 별칭으로도 정렬할 수 있습니다.
ORDER BY를 활용하면 데이터가 더 읽기 쉽고 원하는 순서대로 정렬된 결과를 얻을 수 있어 분석과 가독성에 큰 도움이 됩니다.
OFFSET과 LIMIT
OFFSET과 LIMIT은 SQL에서 결과 집합의 특정 부분만 가져오기 위해 사용하는 절입니다. 주로 페이징 기능을 구현할 때 유용하게 사용됩니다. 이 두 절을 결합하여, 예를 들어 10개의 데이터 중 특정 위치에서 시작하여 일부 데이터만 가져오는 것이 가능합니다.
기본 개념
- LIMIT: 결과에서 가져올 행의 개수를 제한합니다.
- OFFSET: 건너뛸 행의 개수를 지정합니다.
기본 문법
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명
ORDER BY 컬럼명 [ASC|DESC]
LIMIT 가져올_행_수 OFFSET 건너뛸_행_수;
LIMIT은 가져올 데이터의 최대 행 수를 제한합니다.OFFSET은 몇 개의 행을 건너뛸지 지정합니다. 이 옵션을 사용하지 않으면 첫 행부터 시작합니다.
예제 테이블
employees 테이블을 예로 들어보겠습니다.
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | HR | 60000 |
| 2 | Bob | IT | 75000 |
| 3 | Charlie | Sales | 50000 |
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
| 6 | Frank | HR | 62000 |
| 7 | Grace | IT | 70000 |
| 8 | Helen | Sales | 52000 |
1. LIMIT 사용하기
예를 들어, employees 테이블에서 상위 5개의 행만 가져오려면 LIMIT을 사용할 수 있습니다.
SELECT *
FROM employees
LIMIT 5;
결과:
| id | name | department | salary |
|—–|————|————|——–|
| 1 | Alice | HR | 60000 |
| 2 | Bob | IT | 75000 |
| 3 | Charlie | Sales | 50000 |
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
위 쿼리는 employees 테이블의 상위 5개 행만 가져옵니다.
2. OFFSET 사용하기
OFFSET을 사용하면 몇 개의 행을 건너뛸지 지정할 수 있습니다. 예를 들어, 상위 3개의 행을 건너뛰고 이후 데이터를 가져오려면 다음과 같이 작성합니다.
SELECT *
FROM employees
OFFSET 3;
결과:
| id | name | department | salary |
|—–|——–|————|——–|
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
| 6 | Frank | HR | 62000 |
| 7 | Grace | IT | 70000 |
| 8 | Helen | Sales | 52000 |
이 쿼리는 상위 3개의 행을 건너뛰고, 나머지 모든 행을 가져옵니다.
3. LIMIT과 OFFSET을 함께 사용하여 페이징하기
LIMIT과 OFFSET을 함께 사용하면 특정 구간의 데이터를 가져올 수 있습니다. 예를 들어, 4번째 행부터 시작하여 3개의 행만 가져오고 싶다면 다음과 같이 작성할 수 있습니다.
SELECT *
FROM employees
LIMIT 3 OFFSET 3;
결과:
| id | name | department | salary |
|—–|——–|————|——–|
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
| 6 | Frank | HR | 62000 |
이 쿼리는 상위 3개의 행을 건너뛰고, 그다음 3개의 행만 가져옵니다. 이를 통해 결과를 페이지 단위로 나누어 가져올 수 있습니다.
실용적인 예시 - 페이징 구현
페이징 기능을 구현할 때 LIMIT과 OFFSET을 사용할 수 있습니다. 예를 들어, 페이지 크기가 3이고 페이지 번호가 n인 경우, OFFSET은 (n - 1) * 3, LIMIT은 3으로 설정합니다.
SELECT *
FROM employees
ORDER BY id
LIMIT 3 OFFSET (n - 1) * 3;
여기서:
LIMIT 3은 한 페이지에 표시할 최대 행 수(예: 3개)입니다.OFFSET (n - 1) * 3은 페이지 번호에 맞는 첫 번째 행을 지정합니다.
요약
- LIMIT: 결과에서 최대 몇 개의 행을 가져올지 제한합니다.
- OFFSET: 특정 수의 행을 건너뛰고 그다음부터 데이터를 가져옵니다.
- 이 두 절은 특히 페이징 처리에 유용하며, 원하는 위치에서부터 일정 개수만큼의 데이터를 조회하는 데 활용됩니다.
Unions and Intersections with Sets
UNION은 SQL에서 두 개 이상의 쿼리 결과를 결합하여 하나의 결과 집합으로 만드는 연산자입니다. 각 쿼리의 결과를 하나의 테이블처럼 병합하여 표시할 때 사용됩니다. UNION을 사용하면 중복된 행은 제거되고, 고유한 행들만 결과로 남게 됩니다.
기본 구조
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명1
UNION
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명2;
UNION의 주요 특징
- 열 개수 및 데이터 타입 일치:
UNION을 사용하는 두 쿼리는 동일한 개수의 열을 반환해야 하며, 각각의 열의 데이터 타입도 일치해야 합니다. - 중복 제거: 기본적으로
UNION은 결과 집합에서 중복된 행을 제거합니다. - 결과 순서:
UNION을 통해 결합된 결과는 첫 번째 쿼리 결과가 먼저 표시되고, 그 뒤에 두 번째 쿼리 결과가 이어집니다.
예시 테이블
예를 들어, 두 개의 테이블 employees와 managers가 있다고 가정합니다.
employees 테이블
| id | name | department |
|—–|———-|————|
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Charlie | Sales |
managers 테이블
| id | name | department |
|—–|———-|————|
| 1 | Diana | IT |
| 2 | Edward | Sales |
| 3 | Frank | HR |
1. 기본적인 UNION 사용
두 테이블의 모든 name과 department 정보를 결합하고, 중복을 제거하여 하나의 결과로 표시하고 싶다면 다음과 같이 UNION을 사용할 수 있습니다:
SELECT name, department
FROM employees
UNION
SELECT name, department
FROM managers;
결과:
| name | department |
|———|————|
| Alice | HR |
| Bob | IT |
| Charlie | Sales |
| Diana | IT |
| Edward | Sales |
| Frank | HR |
여기서 UNION은 employees와 managers 테이블에서 모든 name과 department 값을 결합하고, 중복되는 행은 제거합니다.
2. UNION ALL 사용
중복된 데이터를 포함한 모든 행을 결합하고 싶을 때는 UNION ALL을 사용합니다. UNION ALL은 중복된 행도 포함하여 두 쿼리 결과를 결합합니다.
SELECT name, department
FROM employees
UNION ALL
SELECT name, department
FROM managers;
결과:
| name | department |
|———|————|
| Alice | HR |
| Bob | IT |
| Charlie | Sales |
| Diana | IT |
| Edward | Sales |
| Frank | HR |
UNION과 달리, UNION ALL은 중복된 값도 모두 포함하므로 데이터가 더 많을 수 있습니다.
3. ORDER BY와 함께 사용
UNION을 사용하여 결합된 결과를 정렬하려면, 마지막에 ORDER BY를 사용해야 합니다. 각 쿼리마다 ORDER BY를 추가할 수는 없으며, 결합된 최종 결과에 대해서만 정렬이 가능합니다.
예를 들어, name 기준으로 오름차순 정렬하려면 다음과 같이 작성합니다:
SELECT name, department
FROM employees
UNION
SELECT name, department
FROM managers
ORDER BY name;
결과:
| name | department |
|———|————|
| Alice | HR |
| Bob | IT |
| Charlie | Sales |
| Diana | IT |
| Edward | Sales |
| Frank | HR |
여기서 ORDER BY name은 UNION의 최종 결합 결과를 name을 기준으로 정렬합니다.
4. 컬럼 수와 데이터 타입 일치 필요성
UNION을 사용할 때는 각 쿼리에서 선택하는 컬럼 수와 데이터 타입이 일치해야 합니다. 예를 들어, employees에서 name과 department를 선택한 후 managers에서 name과 department를 선택했지만, 하나의 쿼리에서 열을 추가하거나 다른 데이터 타입을 사용하는 경우 오류가 발생합니다.
요약
- UNION: 두 쿼리 결과를 결합하여 중복을 제거하고 고유한 결과를 반환합니다.
- UNION ALL: 두 쿼리 결과를 결합하여 중복을 포함한 모든 결과를 반환합니다.
- ORDER BY:
UNION결과 전체에 대해 정렬이 가능하며, 마지막에 작성합니다. - 컬럼 수와 데이터 타입 일치 필요: 각 쿼리가 동일한 컬럼 수와 데이터 타입을 반환해야 합니다.
UNION은 서로 다른 테이블에서 데이터를 결합할 때, 특히 페더레이션 데이터베이스 시스템 또는 데이터 분석에 유용하게 사용됩니다.
INTERSECT, INTERSECT ALL, EXCEPT, EXCEPT ALL은 SQL에서 두 쿼리의 결과 집합을 비교하여 교집합이나 차집합을 추출하는 연산자들입니다. 이러한 연산자들은 데이터 집합 간의 관계를 비교할 때 매우 유용합니다.
각 연산자의 기능을 하나씩 살펴보겠습니다.
1. INTERSECT
- 교집합을 구하는 연산자입니다.
- 두 쿼리의 결과에서 공통으로 존재하는 행만 반환합니다.
- 중복된 행은 한 번만 표시됩니다.
기본 문법
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명1
INTERSECT
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명2;
예시
employees와 managers 테이블에서 name과 department가 같은 행이 존재할 경우 해당 행만 반환합니다.
SELECT name, department
FROM employees
INTERSECT
SELECT name, department
FROM managers;
결과:
| name | department |
|——–|————|
| Frank | HR |
이 예시는 두 테이블에서 name과 department가 일치하는 Frank만 반환합니다.
2. INTERSECT ALL
- 두 쿼리의 결과에서 공통으로 존재하는 행을 모든 중복을 포함하여 반환합니다.
- 즉, 동일한 행이 여러 번 등장하는 경우, 그 반복 횟수도 그대로 유지됩니다.
기본 문법
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명1
INTERSECT ALL
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명2;
예시
위와 동일하게 employees와 managers 테이블에서 name과 department가 같은 행이 있으면 중복을 포함하여 모든 행을 반환합니다.
SELECT name, department
FROM employees
INTERSECT ALL
SELECT name, department
FROM managers;
만약 employees와 managers 테이블에 동일한 name, department 값이 여러 번 존재한다면, 그 중복이 모두 포함됩니다.
3. EXCEPT
- 두 쿼리의 결과에서 첫 번째 쿼리에는 있지만 두 번째 쿼리에는 없는 행을 반환합니다.
- 중복된 행은 한 번만 표시됩니다.
기본 문법
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명1
EXCEPT
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명2;
예시
employees 테이블에는 있지만 managers 테이블에는 없는 name과 department 값을 가져옵니다.
SELECT name, department
FROM employees
EXCEPT
SELECT name, department
FROM managers;
결과:
| name | department |
|———|————|
| Alice | HR |
| Bob | IT |
| Charlie | Sales |
이 예시는 employees 테이블의 name, department 값 중 managers 테이블에 없는 값만 반환합니다.
4. EXCEPT ALL
- 두 쿼리의 결과에서 첫 번째 쿼리에는 있지만 두 번째 쿼리에는 없는 행을 중복을 포함하여 반환합니다.
- 동일한 행이 여러 번 등장하는 경우, 그 반복 횟수도 그대로 유지됩니다.
기본 문법
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명1
EXCEPT ALL
SELECT 컬럼명1, 컬럼명2, ...
FROM 테이블명2;
예시
employees 테이블에는 있지만 managers 테이블에는 없는 행을 모두 중복을 포함하여 가져옵니다.
SELECT name, department
FROM employees
EXCEPT ALL
SELECT name, department
FROM managers;
만약 employees 테이블에 특정 name, department 조합이 여러 번 등장하고, managers 테이블에는 없는 경우, 그 중복이 모두 포함되어 반환됩니다.
요약
- INTERSECT: 두 쿼리의 교집합을 반환하며, 중복된 행은 한 번만 반환합니다.
- INTERSECT ALL: 두 쿼리의 교집합을 반환하며, 중복된 행을 모두 포함합니다.
- EXCEPT: 첫 번째 쿼리에는 있지만 두 번째 쿼리에는 없는 행을 반환하며, 중복된 행은 한 번만 반환합니다.
- EXCEPT ALL: 첫 번째 쿼리에는 있지만 두 번째 쿼리에는 없는 행을 중복을 포함하여 모두 반환합니다.
이 연산자들을 통해 데이터 집합 간의 차이점이나 공통점을 쉽게 분석할 수 있습니다.
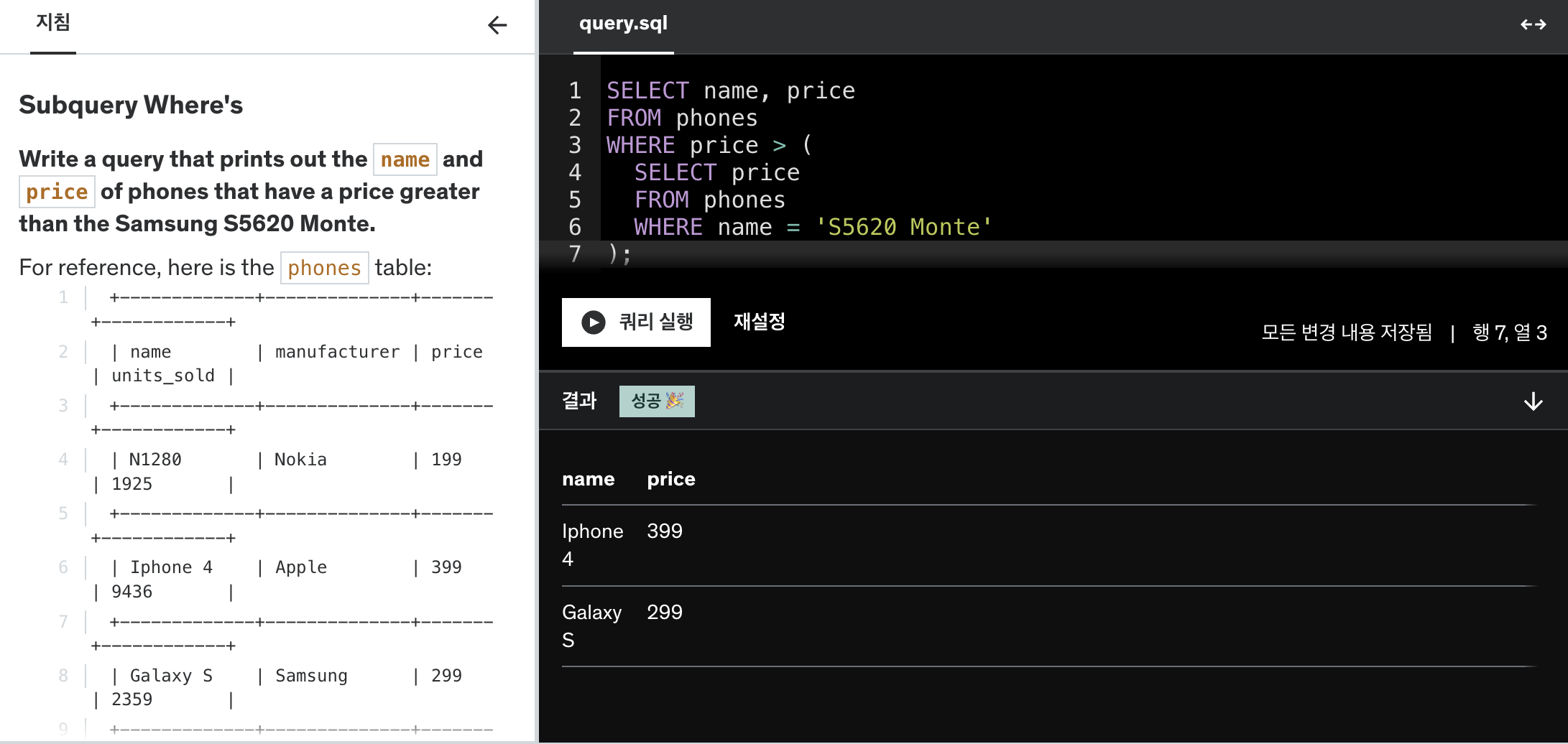
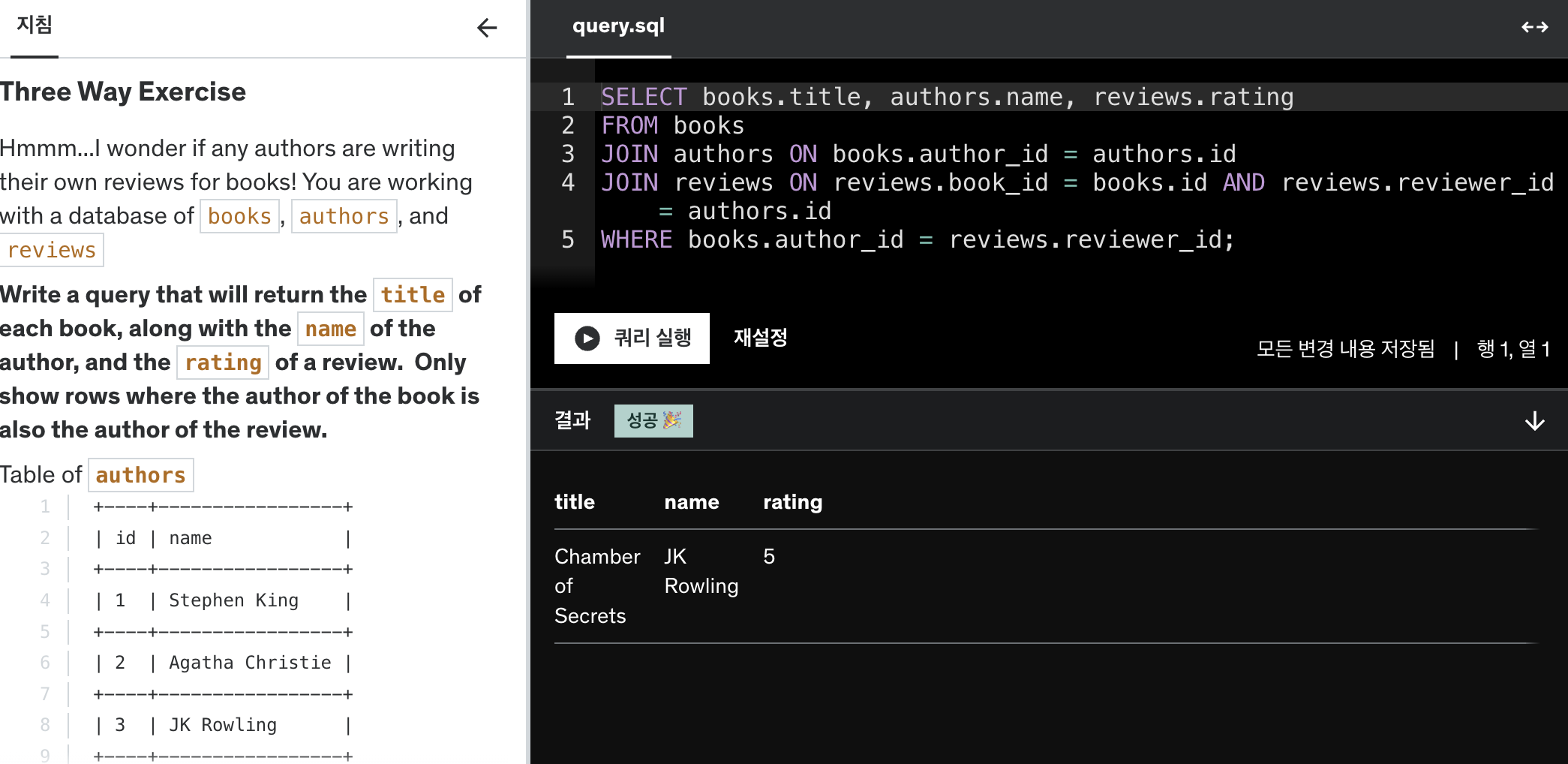
Assembling Queries with Subqueries
Subquery(서브쿼리)는 쿼리 안에 포함된 또 다른 쿼리로, 주 쿼리의 결과를 구하기 위해 필요한 중간 결과를 제공합니다. 서브쿼리는 종종 괄호 () 안에 작성되며, 주 쿼리의 일부로 작동하여 주 쿼리의 조건이나 값을 제공하는 역할을 합니다.
서브쿼리는 다양한 방식으로 활용할 수 있으며, 크게 SELECT 절, WHERE 절, FROM 절, HAVING 절 등에서 사용할 수 있습니다.
Subquery의 기본 형태
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 = (SELECT 컬럼명 FROM 다른_테이블 WHERE 조건);
서브쿼리의 종류
서브쿼리는 사용 위치에 따라 크게 세 가지로 나눌 수 있습니다.
- 스칼라 서브쿼리: 단일 값(스칼라 값)을 반환하는 서브쿼리로, 주로 조건절이나 계산에 사용됩니다.
- 다중 행 서브쿼리: 여러 행을 반환하는 서브쿼리로,
IN,ANY,ALL과 같은 연산자와 함께 사용됩니다. - 다중 열 서브쿼리: 여러 행과 열을 반환하며, 주로
EXISTS절이나JOIN과 함께 사용됩니다.
서브쿼리 사용 예시
예시 테이블
두 개의 테이블, employees와 departments가 있다고 가정합니다.
employees 테이블
| id | name | department_id | salary |
|—–|———|—————|——–|
| 1 | Alice | 1 | 60000 |
| 2 | Bob | 2 | 75000 |
| 3 | Charlie | 2 | 50000 |
| 4 | Diana | 3 | 80000 |
| 5 | Edward | 1 | 55000 |
departments 테이블
| id | department_name |
|—–|——————|
| 1 | HR |
| 2 | IT |
| 3 | Sales |
1. WHERE 절에서의 서브쿼리 사용
예를 들어, IT 부서에 속한 직원의 이름과 급여를 가져오고 싶다면, departments 테이블에서 department_id를 찾기 위한 서브쿼리를 사용할 수 있습니다.
SELECT name, salary
FROM employees
WHERE department_id = (SELECT id FROM departments WHERE department_name = 'IT');
이 쿼리에서:
SELECT id FROM departments WHERE department_name = 'IT'는departments테이블에서IT부서의id를 찾아 반환합니다.employees테이블의department_id와 일치하는 직원의name과salary를 가져옵니다.
결과:
| name | salary |
|———|——–|
| Bob | 75000 |
| Charlie | 50000 |
2. SELECT 절에서의 서브쿼리 사용
각 직원의 급여와 함께 회사에서 가장 높은 급여를 함께 표시하려면 SELECT 절에서 서브쿼리를 사용할 수 있습니다.
SELECT name, salary,
(SELECT MAX(salary) FROM employees) AS highest_salary
FROM employees;
이 쿼리에서:
(SELECT MAX(salary) FROM employees)는employees테이블에서 가장 높은 급여를 반환합니다.- 각 직원의
name,salary와 회사에서 가장 높은 급여(highest_salary)를 함께 보여줍니다.
결과:
| name | salary | highest_salary |
|———|——–|—————-|
| Alice | 60000 | 80000 |
| Bob | 75000 | 80000 |
| Charlie | 50000 | 80000 |
| Diana | 80000 | 80000 |
| Edward | 55000 | 80000 |
3. FROM 절에서의 서브쿼리 사용
서브쿼리를 FROM 절에 사용하여 일종의 가상 테이블을 생성할 수 있습니다. 예를 들어, 각 부서별 평균 급여를 계산하는 서브쿼리를 FROM 절에 작성하여 각 직원의 급여가 해당 부서의 평균 급여보다 높은 직원만 조회할 수 있습니다.
SELECT e.name, e.salary
FROM employees e
JOIN (SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id) AS dept_avg
ON e.department_id = dept_avg.department_id
WHERE e.salary > dept_avg.avg_salary;
이 쿼리에서:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id는 각 부서의 평균 급여를 계산합니다.- 이 가상 테이블을
dept_avg로 참조하여 각 직원의 급여가 부서 평균보다 높은 경우만 결과에 포함합니다.
결과:
| name | salary |
|———|——–|
| Bob | 75000 |
| Diana | 80000 |
4. EXISTS 서브쿼리
EXISTS는 서브쿼리가 하나 이상의 결과를 반환하는지 여부에 따라 TRUE 또는 FALSE를 반환합니다. 예를 들어, Sales 부서에 직원이 있는지 확인하고 싶을 때 사용할 수 있습니다.
SELECT department_name
FROM departments d
WHERE EXISTS (SELECT 1 FROM employees e WHERE e.department_id = d.id AND d.department_name = 'Sales');
이 쿼리는 Sales 부서에 직원이 있는 경우 해당 부서 이름을 반환합니다.
서브쿼리 요약
- WHERE 절 서브쿼리: 특정 조건에 맞는 값을 찾을 때 사용.
- SELECT 절 서브쿼리: 결과 행에 서브쿼리 값을 추가할 때 사용.
- FROM 절 서브쿼리: 가상 테이블을 생성하여 다양한 조건과 결합할 때 사용.
- EXISTS 서브쿼리: 서브쿼리가 결과를 반환하는지 확인하는 조건문.
서브쿼리는 복잡한 조건을 처리하고 다중 테이블의 데이터를 비교할 때 유용하며, SQL 쿼리 작성 시 유연성을 높여줍니다.
✅ FROM 절에서 서브쿼리를 사용할 때는 반드시 별칭(alias)을 붙여야 합니다.
- SQL은 FROM 절의 서브쿼리를 하나의 가상 테이블로 인식하기 때문에, 별칭이 없으면 서브쿼리를 참조할 수 있는 이름이 없게 됩니다.
- 별칭이 없으면 SQL은 서브쿼리의 결과에 접근할 방법이 없으므로, 오류가 발생합니다.
NOT IN
NOT IN은 SQL에서 지정된 목록이나 서브쿼리의 결과에 포함되지 않는 값을 선택할 때 사용하는 조건입니다. 즉, IN 연산자의 반대 역할을 수행하며, 특정 컬럼의 값이 지정된 값 목록이나 서브쿼리 결과에 없을 때만 해당 행을 반환합니다.
기본 문법
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 NOT IN (값1, 값2, 값3, ...);
또는 서브쿼리를 사용하여 결과 집합에 없는 값만 선택할 수도 있습니다.
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 NOT IN (SELECT 컬럼명 FROM 다른_테이블 WHERE 조건);
예시 테이블
예를 들어, employees와 departments라는 두 개의 테이블이 있다고 가정합니다.
employees 테이블
| id | name | department_id |
|—–|———-|—————|
| 1 | Alice | 1 |
| 2 | Bob | 2 |
| 3 | Charlie | 2 |
| 4 | Diana | 3 |
| 5 | Edward | NULL |
departments 테이블
| id | department_name |
|—–|——————|
| 1 | HR |
| 2 | IT |
| 3 | Sales |
| 4 | Marketing |
1. 값 목록을 사용한 NOT IN
employees 테이블에서 department_id가 2와 3이 아닌 직원들을 조회하고 싶다면 다음과 같이 NOT IN을 사용할 수 있습니다.
SELECT name
FROM employees
WHERE department_id NOT IN (2, 3);
결과:
| name |
|——–|
| Alice |
| Edward |
여기서:
department_id가2와3이 아닌 직원만 조회됩니다.NULL값은NOT IN조건에 포함되지 않으므로department_id가NULL인Edward도 결과에 포함됩니다.
2. 서브쿼리를 사용한 NOT IN
NOT IN은 서브쿼리와 함께 사용하여 다른 테이블에 없는 데이터를 필터링하는 데도 유용합니다. 예를 들어, departments 테이블에 없는 department_id를 가진 직원만 조회하고 싶다면 다음과 같이 작성할 수 있습니다.
SELECT name
FROM employees
WHERE department_id NOT IN (SELECT id FROM departments);
결과:
| name |
|——–|
| Edward |
이 쿼리는:
departments테이블에 존재하지 않는department_id를 가진 직원만 반환합니다.departments에 없는NULL값(department_id가 NULL인 직원Edward)도 포함됩니다.
3. NULL 값과의 관계
NOT IN을 사용할 때 주의할 점은 서브쿼리가 NULL을 포함할 경우입니다. NOT IN 조건에서는 NULL이 포함되면 결과가 예기치 않게 빈 결과가 될 수 있습니다.
예를 들어, 아래와 같은 서브쿼리에서 departments에 NULL이 포함되었다고 가정해 보겠습니다.
SELECT name
FROM employees
WHERE department_id NOT IN (SELECT id FROM departments);
서브쿼리에 NULL이 있으면, SQL은 NOT IN 조건이 만족되지 않는 것으로 간주하여 결과가 비어버릴 수 있습니다. 이를 방지하려면 IS NOT NULL 조건을 서브쿼리에 추가해 NULL 값을 제거해야 합니다.
SELECT name
FROM employees
WHERE department_id NOT IN (SELECT id FROM departments WHERE id IS NOT NULL);
요약
NOT IN은 지정된 값 목록이나 서브쿼리 결과에 없는 값만 조회할 때 사용합니다.- 서브쿼리와 결합하여 다른 테이블에 없는 데이터를 필터링하는 데 유용합니다.
- 서브쿼리에
NULL이 포함될 경우 결과가 의도와 다르게 나올 수 있으므로, 필요에 따라IS NOT NULL조건을 추가해 주어야 합니다.
NOT IN은 특정 값을 제외하고 데이터를 조회하고 싶을 때, 특히 다른 테이블에 없는 데이터를 필터링할 때 매우 유용한 SQL 조건입니다.
ALL
ALL은 서브쿼리와 함께 사용하여 서브쿼리의 모든 결과와 비교하여 조건을 만족하는지 확인하는 연산자입니다. 즉, 특정 조건이 서브쿼리에서 반환된 모든 값에 대해 참인지 확인할 때 사용됩니다.
기본 문법
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 연산자 ALL (서브쿼리);
연산자에는>,<,>=,<=,=등이 사용됩니다.ALL은 서브쿼리가 반환하는 모든 값과 비교하여 조건을 충족하는지 확인합니다.
예시
employees 테이블이 있고 각 직원의 급여가 저장되어 있다고 가정합니다.
employees 테이블
| id | name | salary |
|—–|———-|——–|
| 1 | Alice | 60000 |
| 2 | Bob | 75000 |
| 3 | Charlie | 50000 |
| 4 | Diana | 80000 |
| 5 | Edward | 55000 |
예를 들어, salary가 모든 직원의 급여보다 높은 직원을 찾는 쿼리를 작성하고 싶다면 ALL을 다음과 같이 사용할 수 있습니다:
SELECT name
FROM employees
WHERE salary > ALL (SELECT salary FROM employees);
위 쿼리는 employees 테이블에서 salary가 모든 직원의 급여보다 높은 직원만 조회합니다.
결과:
이 예제에서는 salary가 모든 직원의 급여보다 높은 사람이 없으므로 결과는 비어 있습니다.
예제 2: ALL과 다른 연산자 사용
모든 직원의 급여보다 낮은 급여를 가진 직원을 찾고 싶다면 다음과 같이 ALL과 < 연산자를 사용할 수 있습니다:
SELECT name
FROM employees
WHERE salary < ALL (SELECT salary FROM employees WHERE salary IS NOT NULL);
이 경우는 salary가 모든 직원보다 낮은 Charlie가 결과에 포함됩니다.
요약
ALL은 서브쿼리의 모든 값에 대해 조건을 비교할 때 사용합니다.- 주로
> ALL,< ALL,>= ALL,<= ALL등의 형태로 사용되며, 조건이 서브쿼리의 모든 결과를 만족해야 참이 됩니다. ALL을 통해 서브쿼리의 결과와 전체 비교 조건을 설정할 수 있어 세부적인 필터링이 가능합니다.
SOME
SOME은 SQL에서 서브쿼리의 결과 집합에 대해 특정 조건을 만족하는 값이 하나라도 있는지 확인할 때 사용하는 연산자입니다. ANY와 유사하게 작동하며, 특정 조건을 하나라도 만족하는 경우에 TRUE를 반환합니다.
기본 문법
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 연산자 SOME (서브쿼리);
SOME은=,<,>,<=,>=,<>등의 비교 연산자와 함께 사용됩니다.SOME은 서브쿼리의 결과 중 하나라도 비교 조건을 만족하면TRUE를 반환합니다.- 사실상
SOME과ANY는 동일하게 작동합니다.SOME은ANY의 동의어로, 대부분의 SQL 데이터베이스 시스템에서 둘 중 하나를 선택적으로 사용할 수 있습니다.
예시
예를 들어, employees 테이블에 있는 직원의 salary가 다른 부서 직원 중 하나의 급여보다 높은 직원들을 찾고 싶다고 가정합니다.
예시 테이블
| id | name | department | salary |
|—–|————|————|——–|
| 1 | Alice | HR | 60000 |
| 2 | Bob | IT | 75000 |
| 3 | Charlie | Sales | 50000 |
| 4 | Diana | IT | 80000 |
| 5 | Edward | Sales | 55000 |
쿼리 예시
다른 부서의 급여 중 하나보다 높은 급여를 가진 직원들을 찾으려면 다음과 같이 SOME을 사용할 수 있습니다.
SELECT name, salary
FROM employees
WHERE salary > SOME (SELECT salary FROM employees WHERE department = 'Sales');
이 쿼리에서:
- 서브쿼리는
Sales부서 직원의 모든salary를 반환합니다. SOME은salary > SOME (...)조건을 확인하여, 다른 부서에서Sales부서의 급여 중 하나보다 높은 급여를 가진 직원만 선택합니다.
결과:
| name | salary |
|——–|——–|
| Alice | 60000 |
| Bob | 75000 |
| Diana | 80000 |
이 결과는 Sales 부서의 직원 중 하나보다 높은 급여를 가진 직원들을 반환합니다.
요약
SOME은 서브쿼리 결과 집합 중 하나라도 조건을 만족하는지 확인할 때 사용합니다.SOME은ANY와 같은 방식으로 작동합니다.- 조건을 만족하는 값이 하나라도 있으면
TRUE를 반환하며, 특정 조건을 하나라도 충족하는 데이터를 찾을 때 유용합니다.
 Foreign Key, Joins and Constraints Around Deletion
Foreign Key, Joins and Constraints Around Deletion