Pandas for Data Search - Finding the Relationship Between College Majors and Salaries
데이터 사이언스를 위한 셋업
- 데이터셋을 찾아보고 시각화할 때는 파이썬 노트북 포맷이 잘 맞음
- New ⇨ More ⇨ Google Colaboratory
- 구글 콜랩 노트북에 접근할 수 없거나 자신의 컴퓨터에서 모든 것을 로컬로 실행하려면
아나콘다 설치하기에서 번들로 제공되는 주피터 노트북 사용하기 - 구글 콜랩은 기본적으로 주피터의 온라인 버전
Shift+Enter사용하여 셀을 실행
데이터 업로드와 .cvs 파일 읽기
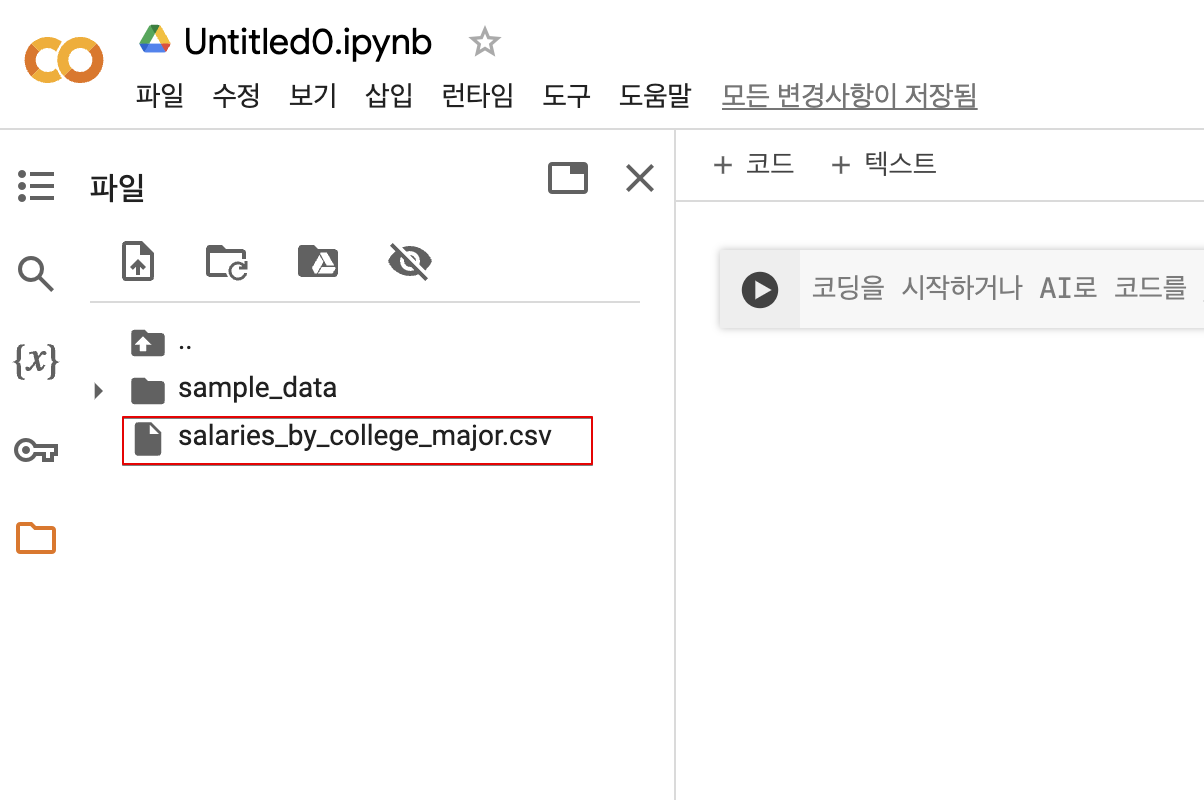
- .csv파일 추가
- 데이터프레임 살펴보기
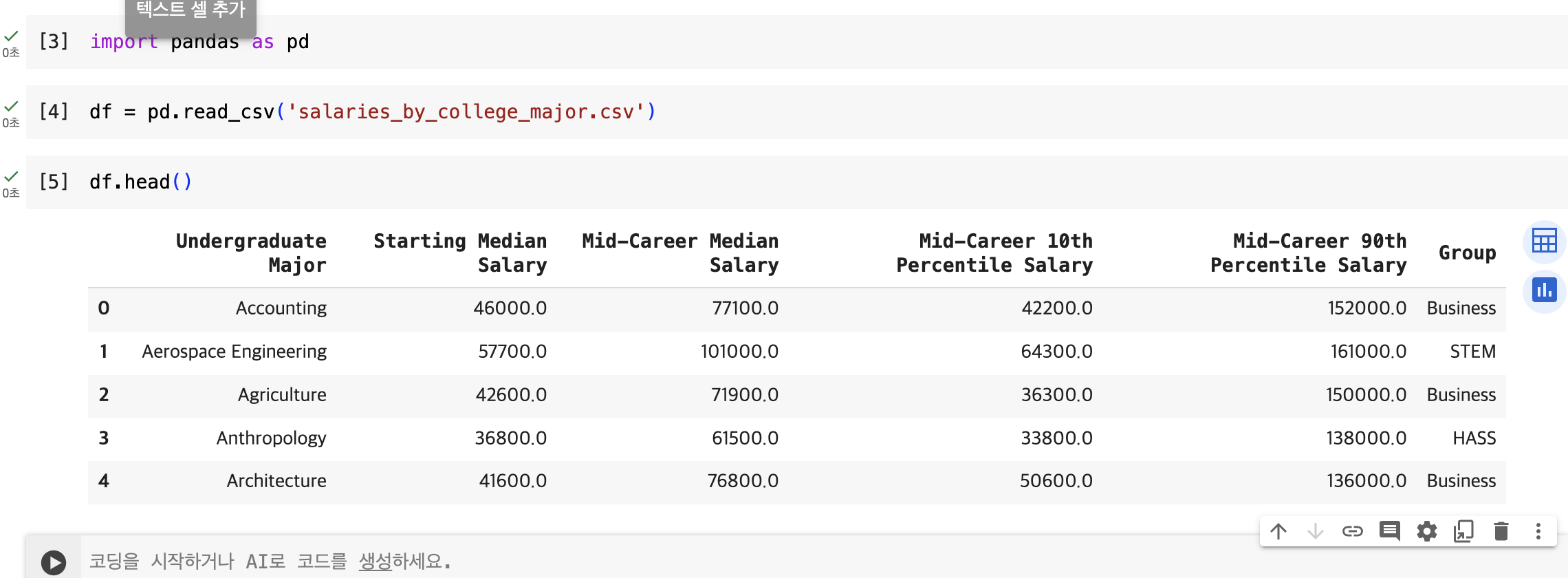
Pandas의 head()
DataFrame 또는 Series 객체의 첫 몇 행을 반환하는 기능
기본적으로, head() 함수는 첫 5행을 반환하지만, 괄호 안에 다른 숫자를 넣어 원하는 행의 수를 지정할 수도 있다. 예를 들어, head(10)은 첫 10행을 반환함
데이터를 빠르게 검토하고, 구조를 이해하는 데 유용하다.
판다스를 이용한 예비 데이터 탐색 및 데이터 정리
✔︎ 데이터 이해하기
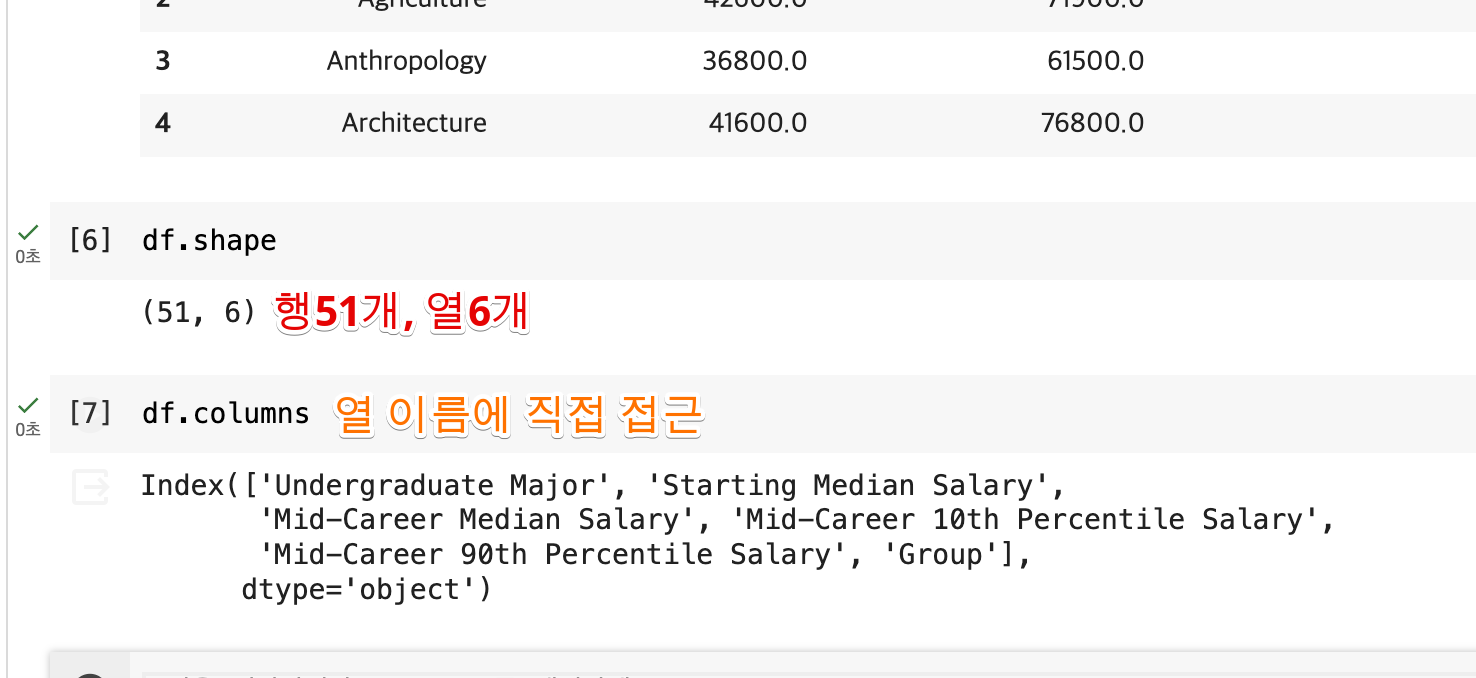
- 데이터프레임에는 몇 개의 행이 있습니까?
- 몇 개의 열이 있나요?
- 열의 레이블은 무엇인가요? 열에 이름이 있나요?
- 데이터프레임에 누락된 값이 있나요? 데이터프레임에 잘못된 데이터가 포함되어 있지는 않나요?
✔︎ shape속성을 이용해 행과 열의 개수보기
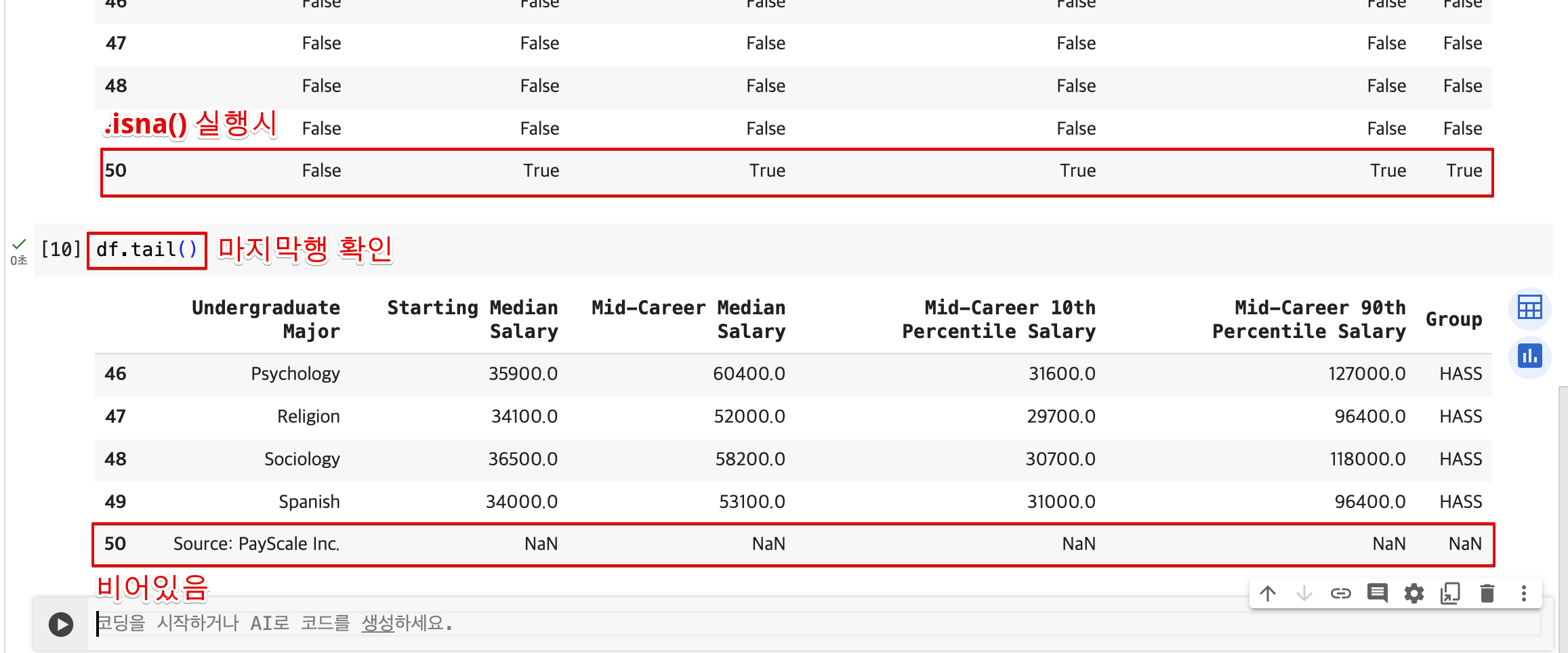
결측값 및 정크 데이터
- 분석을 진행하기 전 데이터프레임에 누락된 데이터 또는 정크 데이터는 없는 지 확인
.isna()메소드를 사용해서 NaN(Not a Number)값 찾기 : 빈 셀 또는 숫자 대신 문자열을 포함하는 셀
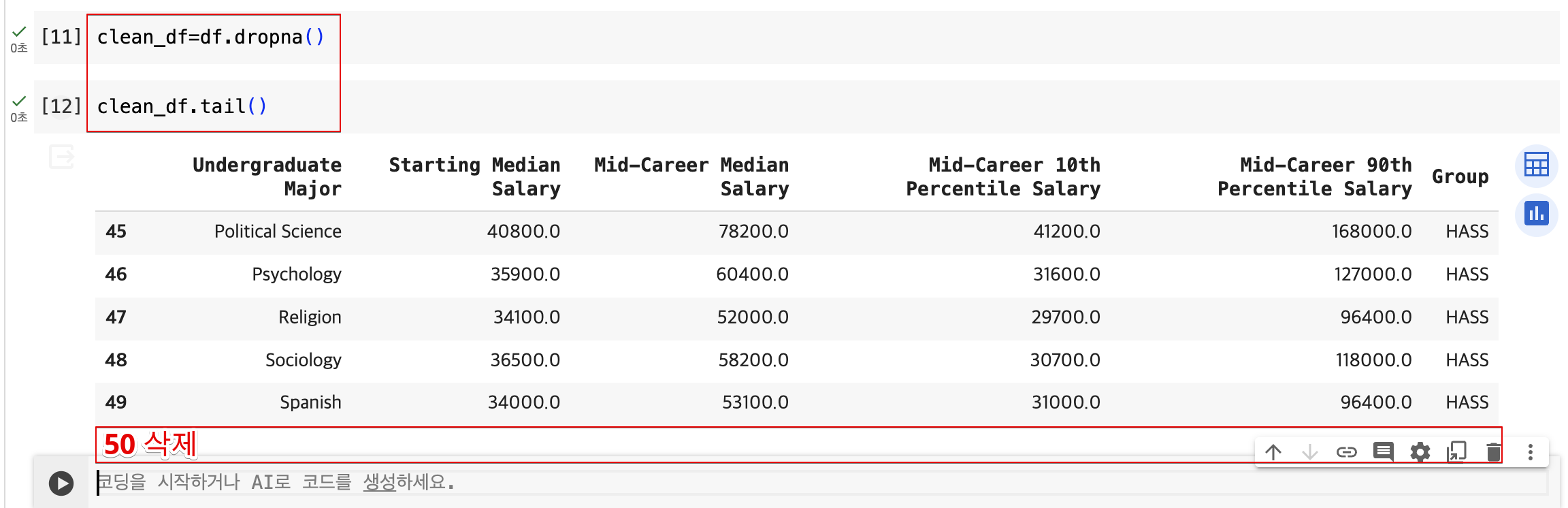
마지막 행 삭제 두 가지 방법
- 인덱스에서 수동으로 삭제
- .dropna()메소드 사용
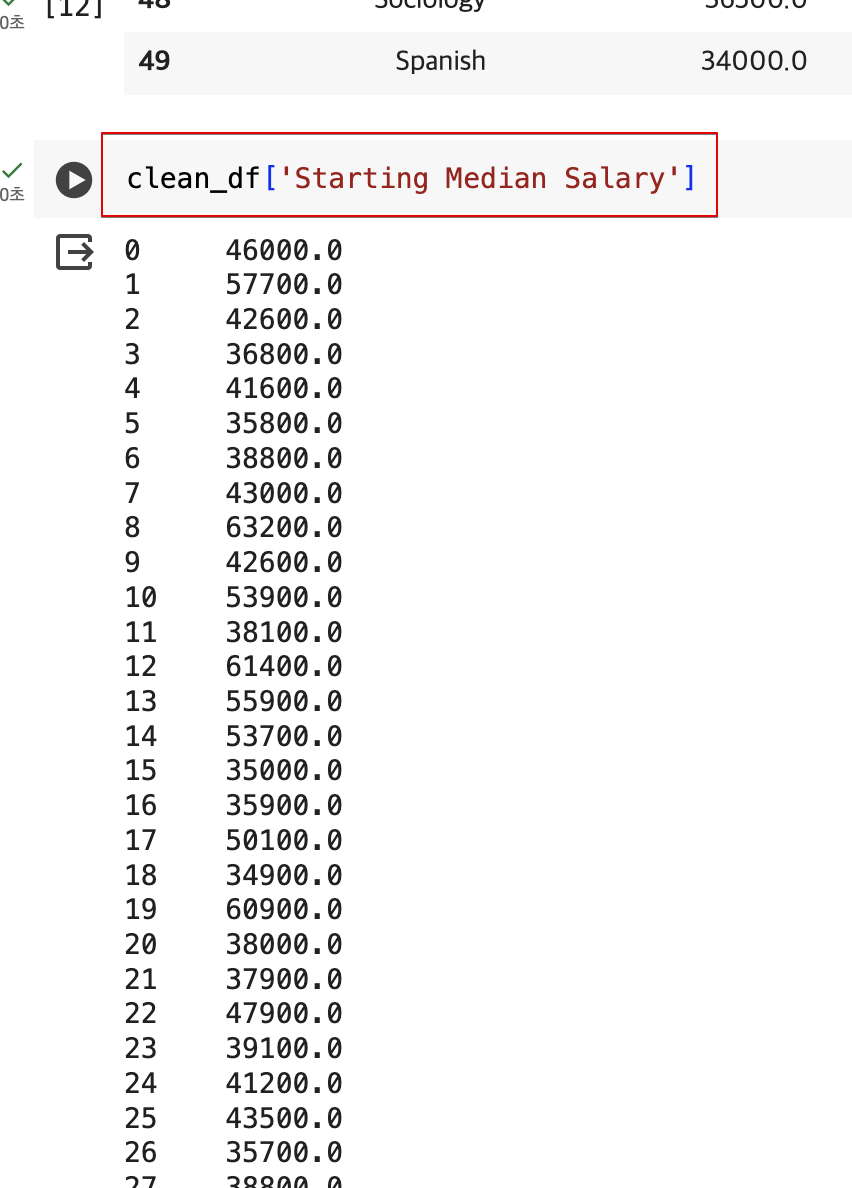
데이터프레임에 있는 열 및 개별 셀에 접근하기
초봉이 가장 높은 대학 전공 찾기
- 특정 열에 접근하려면 다음과 같이 [ ] 표기를 사용할 수 있다.
- 가장 높은 데이터 찾기
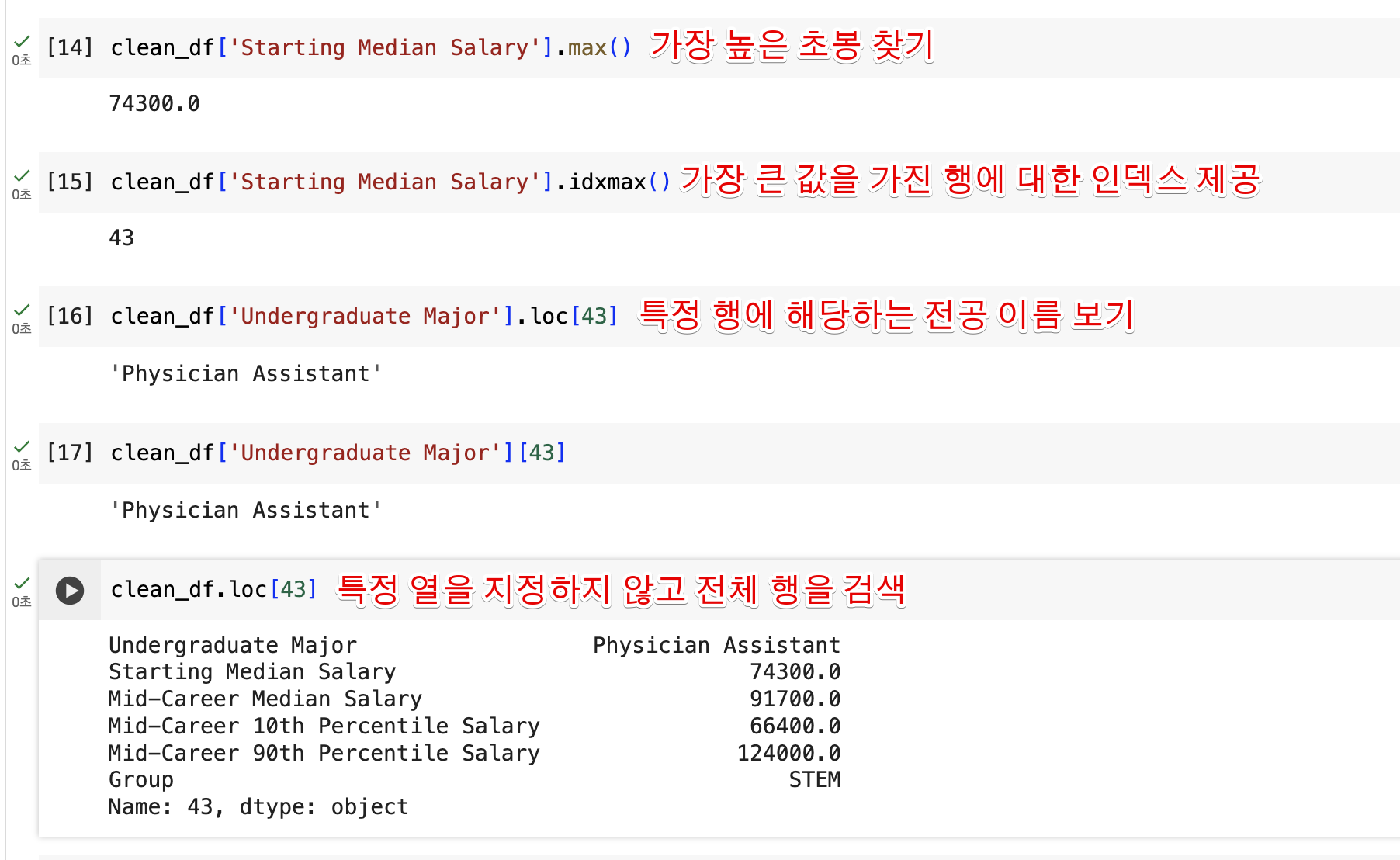
- 가장 낮은 숫자의 데이터 찾기
min(),idxmin()
값 분류 및 열 추가하기 : 잠재력이 가장 큰 전공 vs 위험도가 가장 낮은 전공
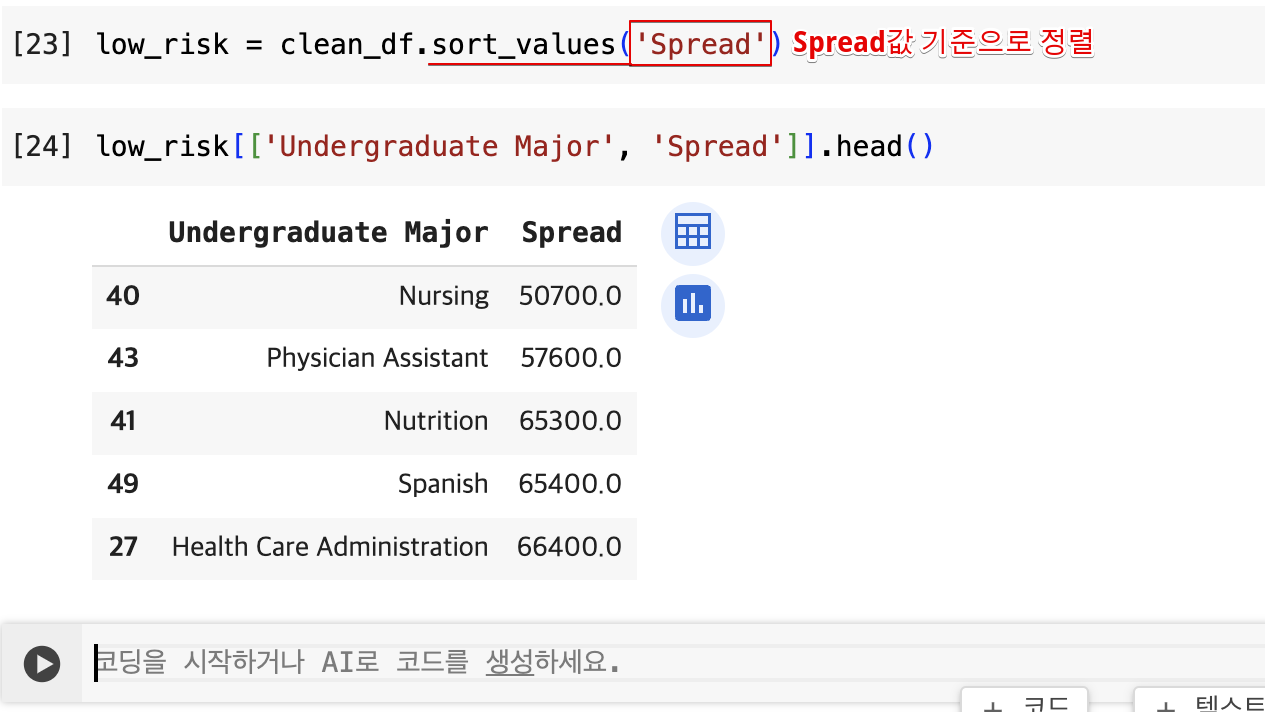
- 위험도가 가장 낮은 전공 : 최저 급여와 최고 급여의 차이가 작은 학위
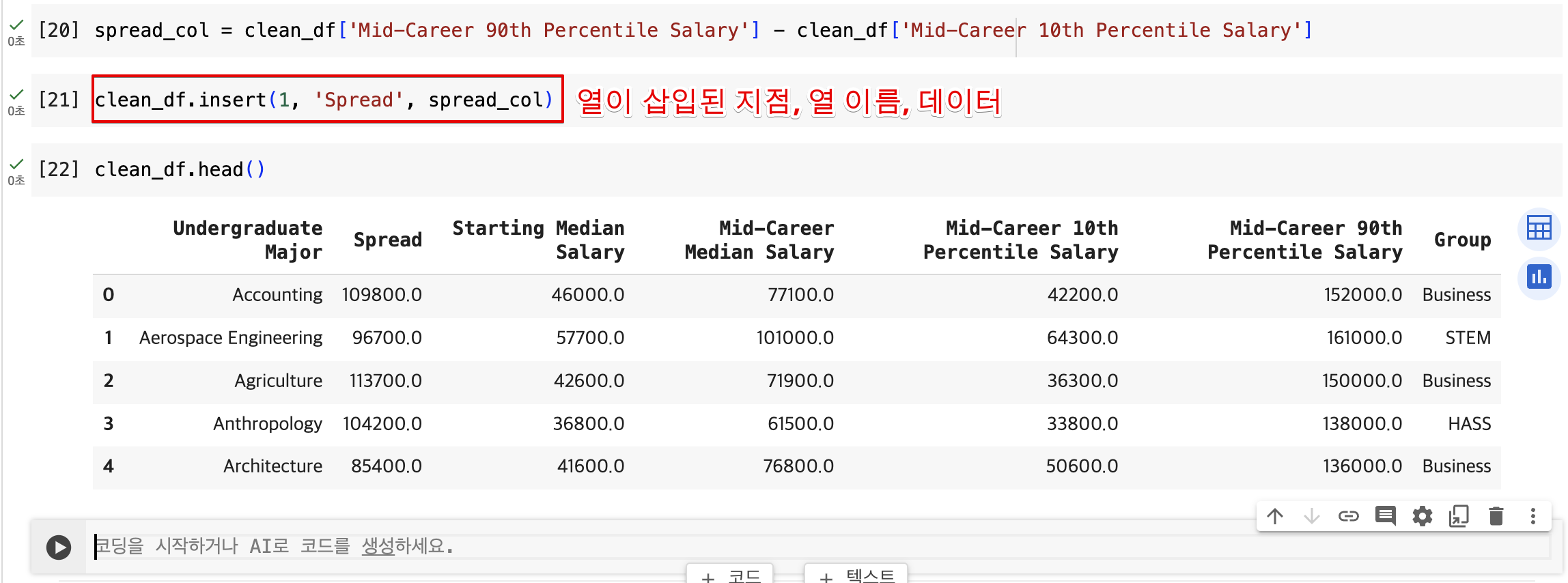
- 10번째 백분위수와 90번째 백분위수 소득 차이
clean_df['Mid-Career 90th Percentile Salary'] - clean_df['Mid-Career 10th Percentile Salary']or
clean_df['Mid-Career 90th Percentile Salary'].subtract(clean_df['Mid-Career 10th Percentile Salary'])
열 추가하기
가장 낮은 분포로 정렬
sort_values()메소드 사용
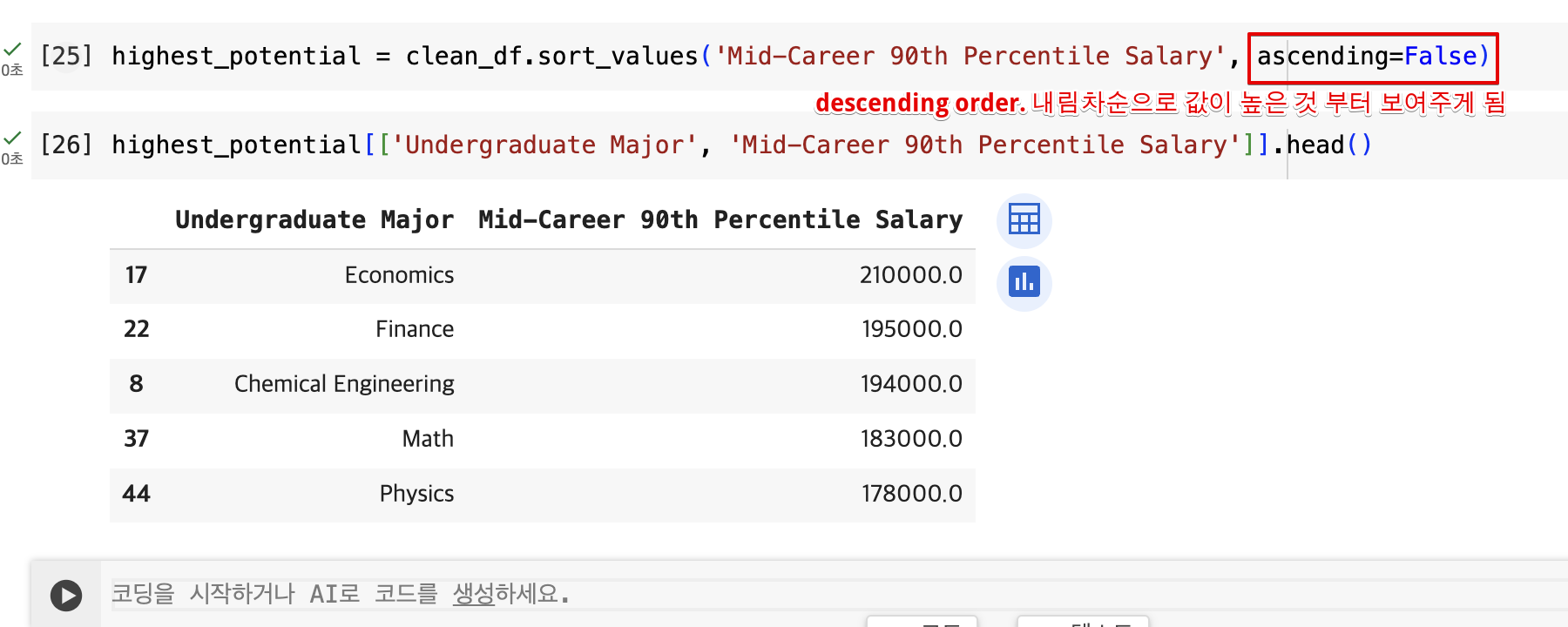
잠재력이 가장 큰 학위
판다스를 이용한 그룹화 및 피벗
- ‘Group’열에 있는 세 가지 법주에 몇 개의 전공이 있는지 계산하기
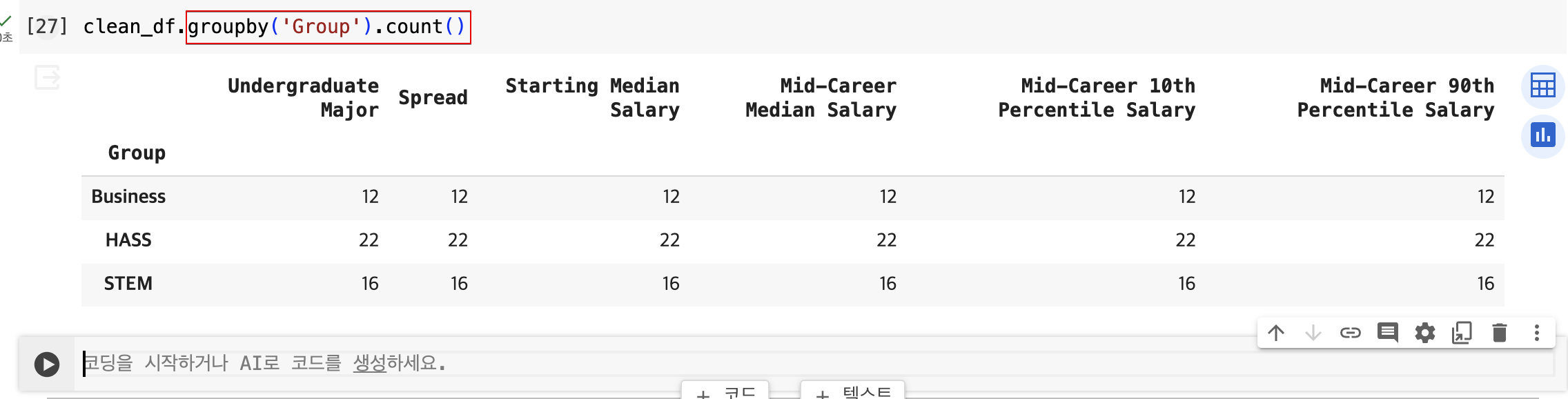
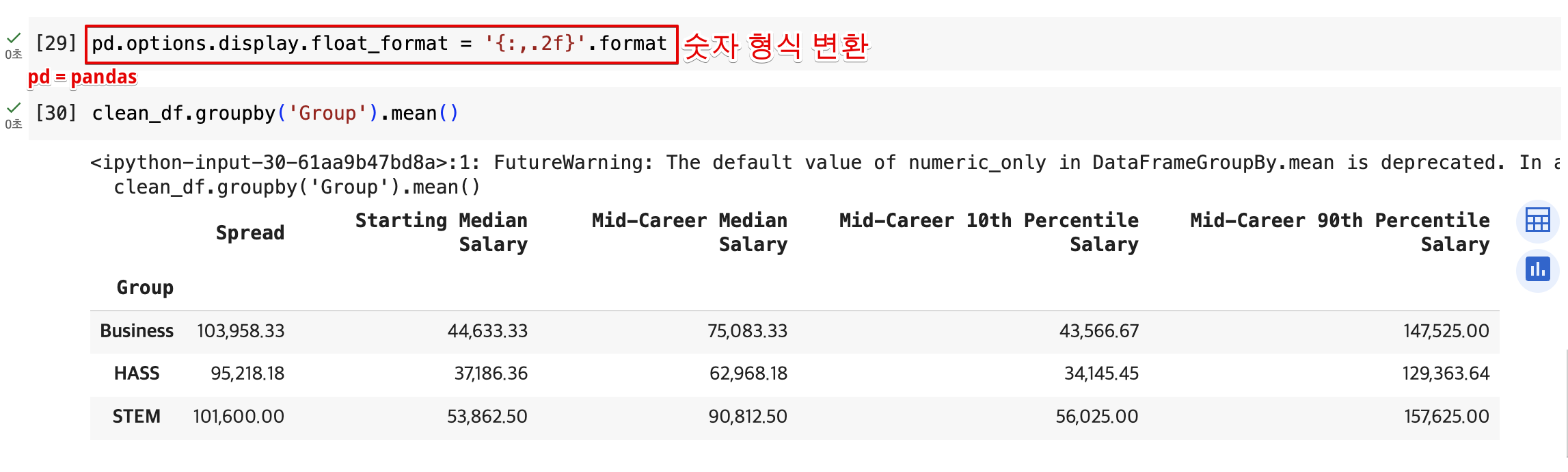
- 평균값 구하기
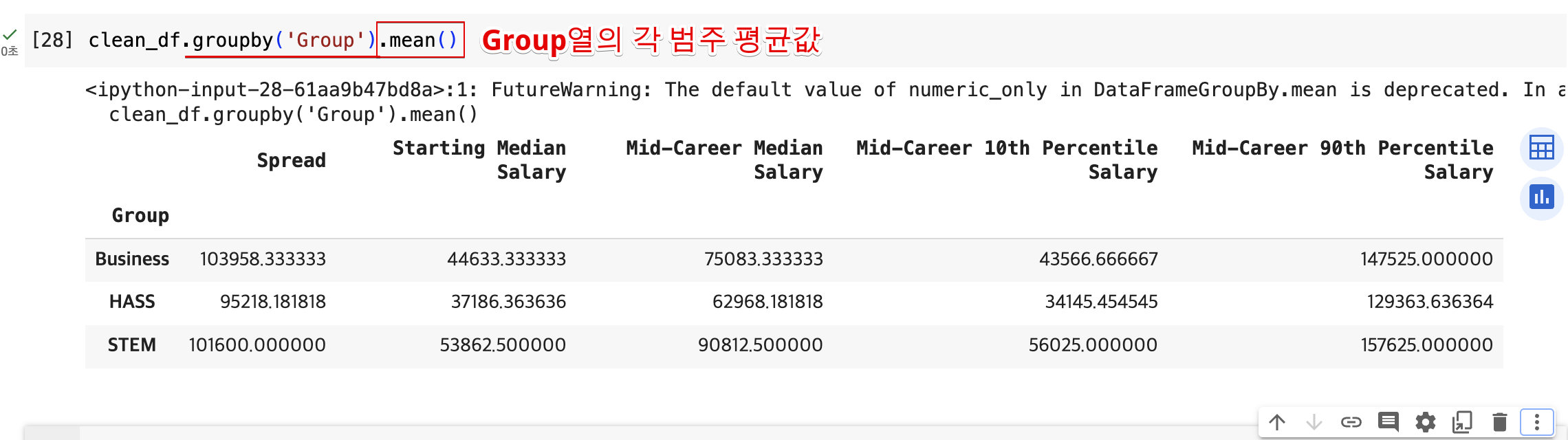
출력에서 숫자 형식