Scraping the Web with BeautifulSoup
BeutifulSoup모듈
- API가 없거나 API로 원하는 작업을 하기 힘들 때 고려할 수 있음
- 웹스크래핑 : 사이트의 HTML 코드를 확인하고 원하는 정보를 얻는 것
- HTML파서. 개발자가 웹사이트를 이해할 수 있도록 도와주는 모듈
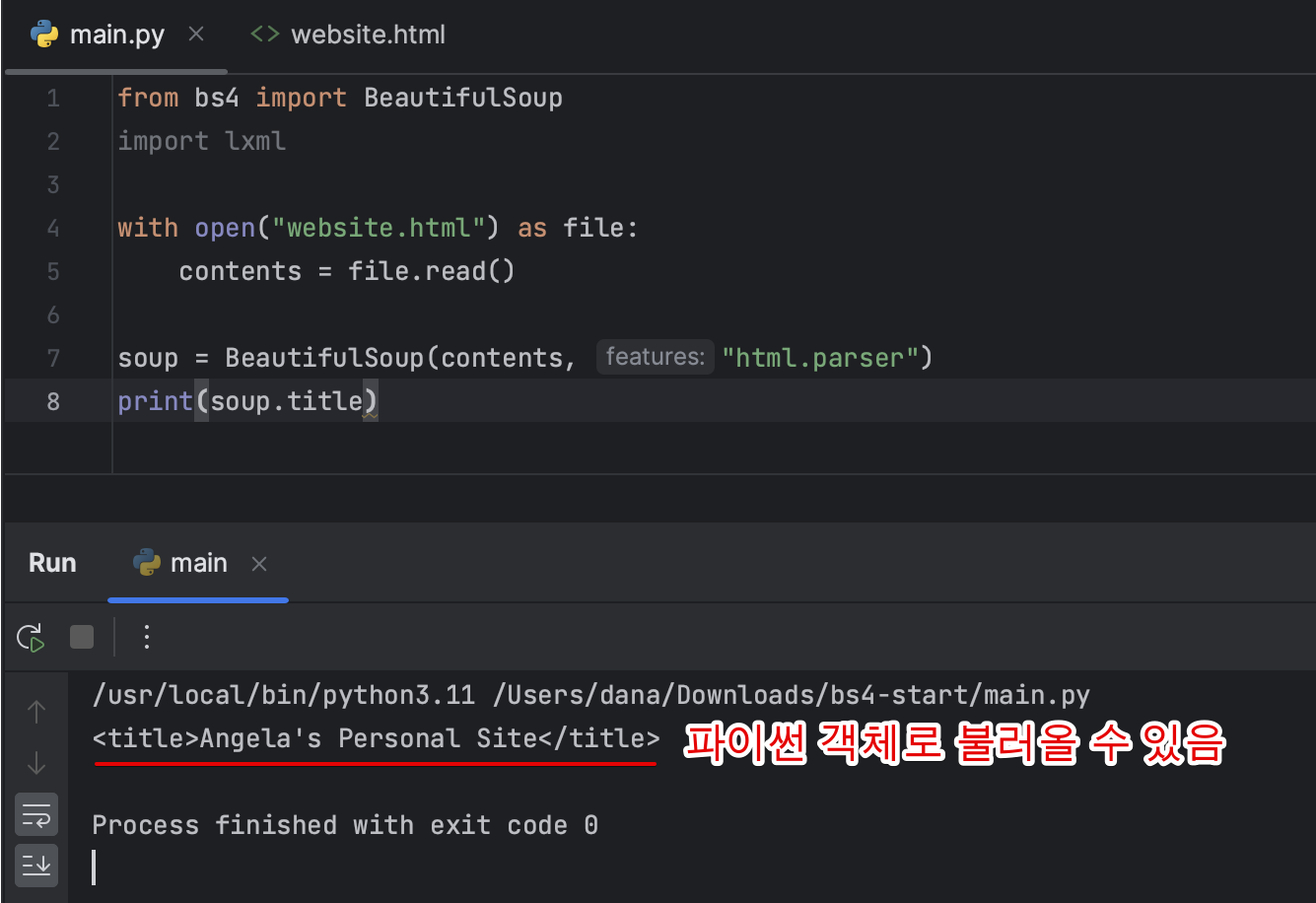
HTML 파싱 및 Soup 만들기
- 파일 불러오기, 클래스 import, 객체 생성
markup
HTML, XML의 M을 의미.
하이퍼텍스트 마크업 언어이며 확장 가능한 마크업 언어
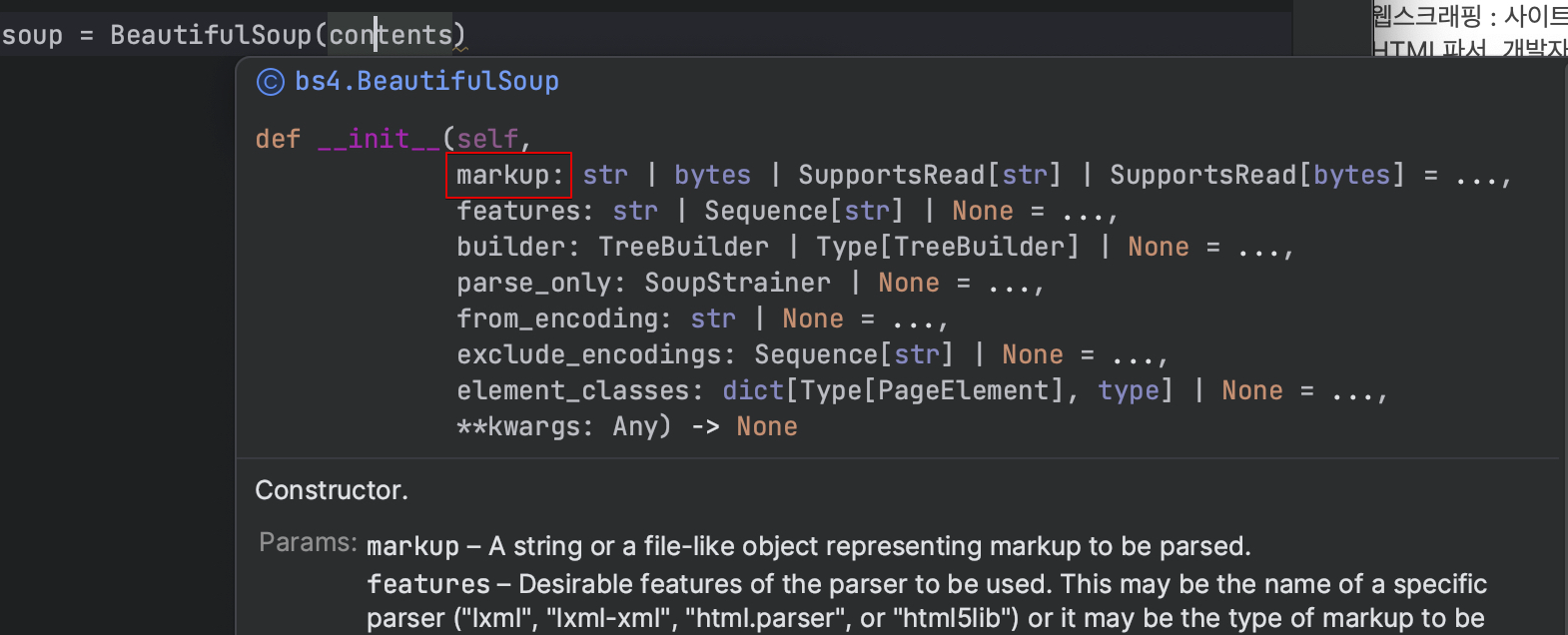
- 경우에 따라서 lxml을 사용해야 할 때도 있음 lxml import
lxml

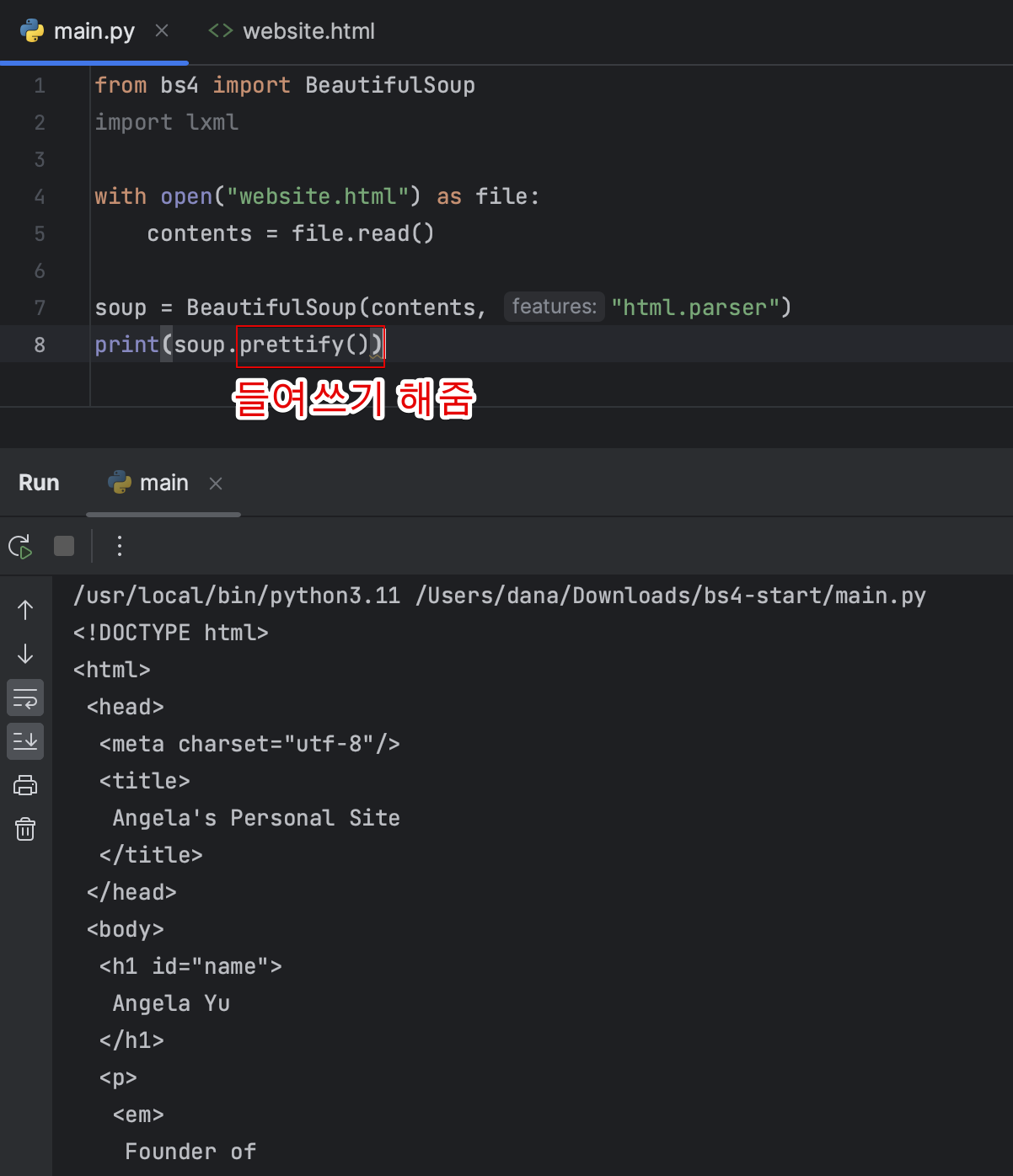
BeautifulSoup으로 특정 요소 찾고 선택하기
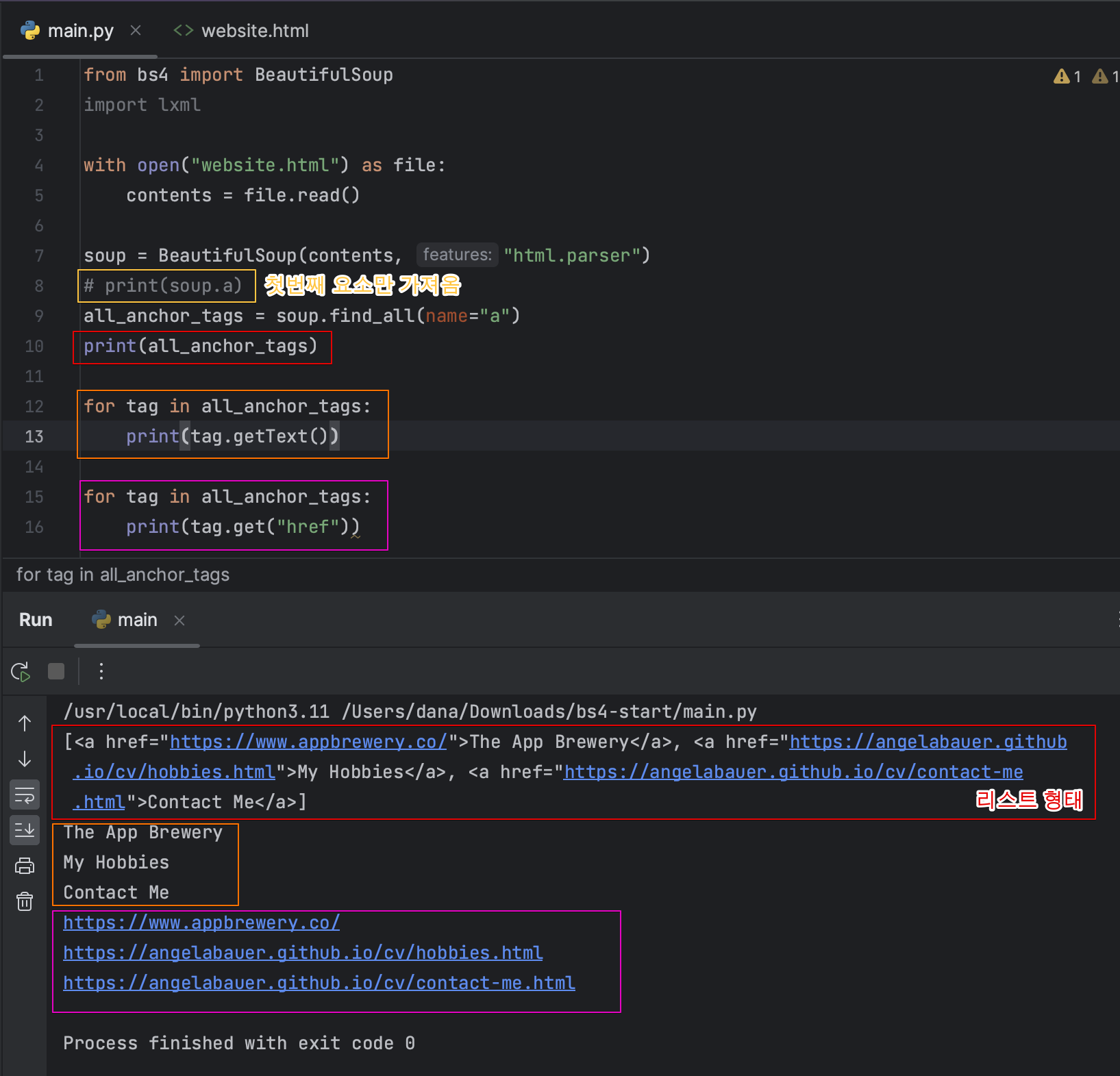
- 첫번째 요소만 가져옴
- 모든 단락을 가져오려면 find_all 함수 사용
- 텍스트만 가져오기
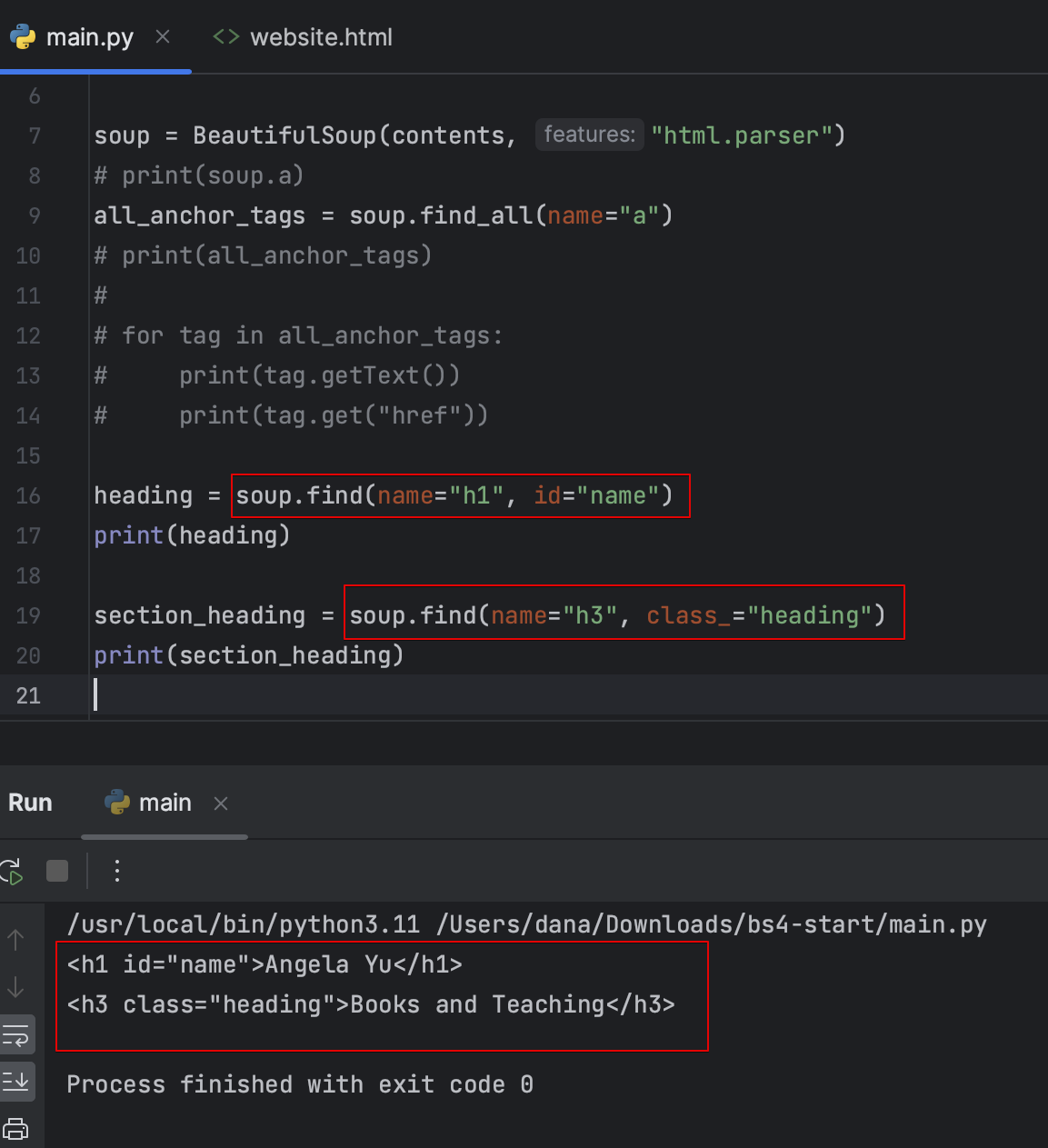
- 속성 이름으로 항목을 검색
class는 예약 키워드(클래스를 생성하는 데먼 사용할 수 있는 특수 단어)이기 때문에 언더바 붙여줌
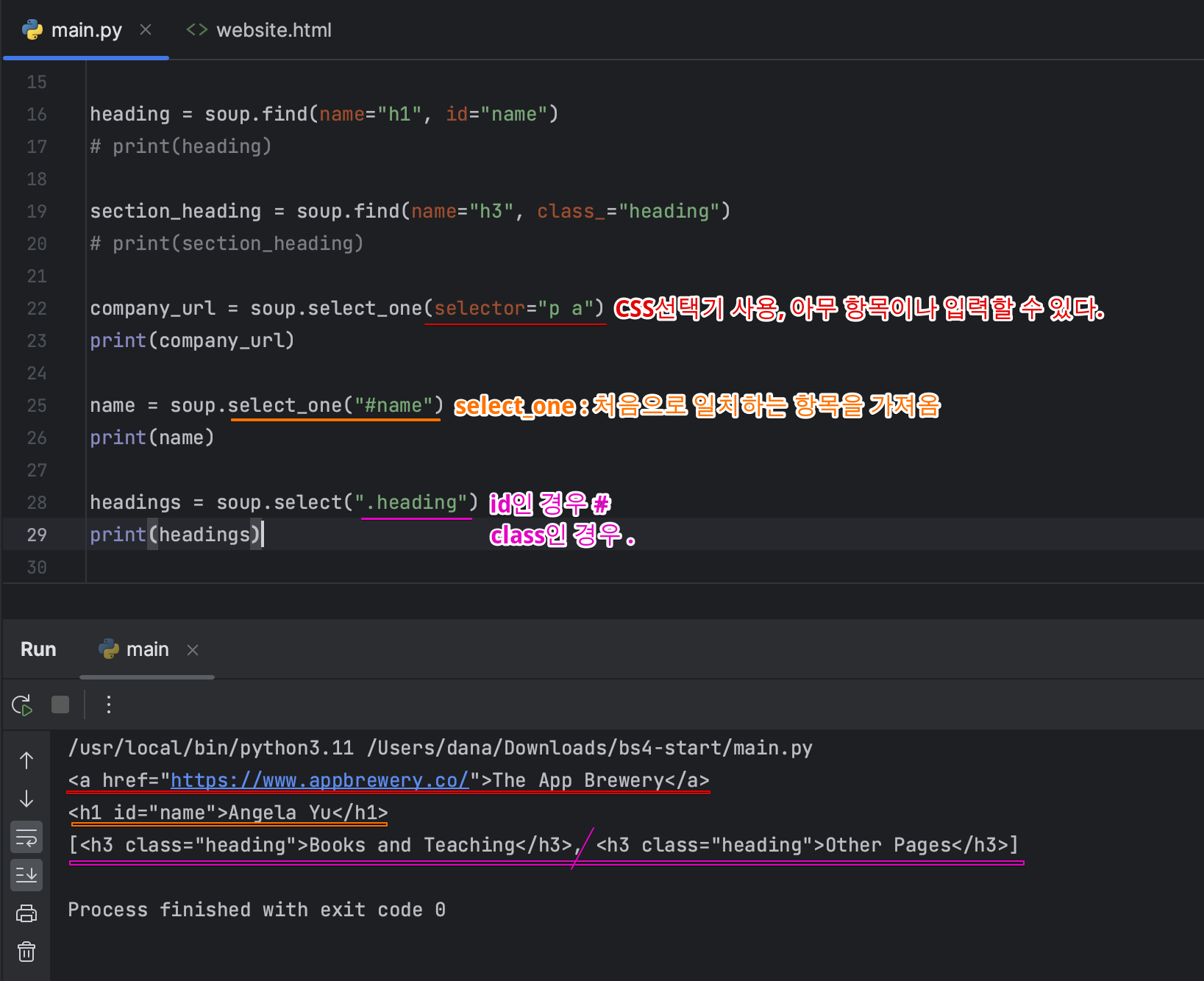
- 속성값을 가져오는 것이 통하지 않는 경우, 특정 태그를 가져오고 싶은 경우
라이브 웹사이트 스크래핑하기
Ycombinator의 Hacker News-기술 관련 뉴스의 링크나 자신이 만든 것을 자랑할 수 있는 웹사이트
제목과 링크, 포인트 스크랩핑 후 포인트가 가장 높은 기사 확인하기
-
데이터를 다운로드 하기 위해 requests import 후 변수에 저장
-
각 값들 받기
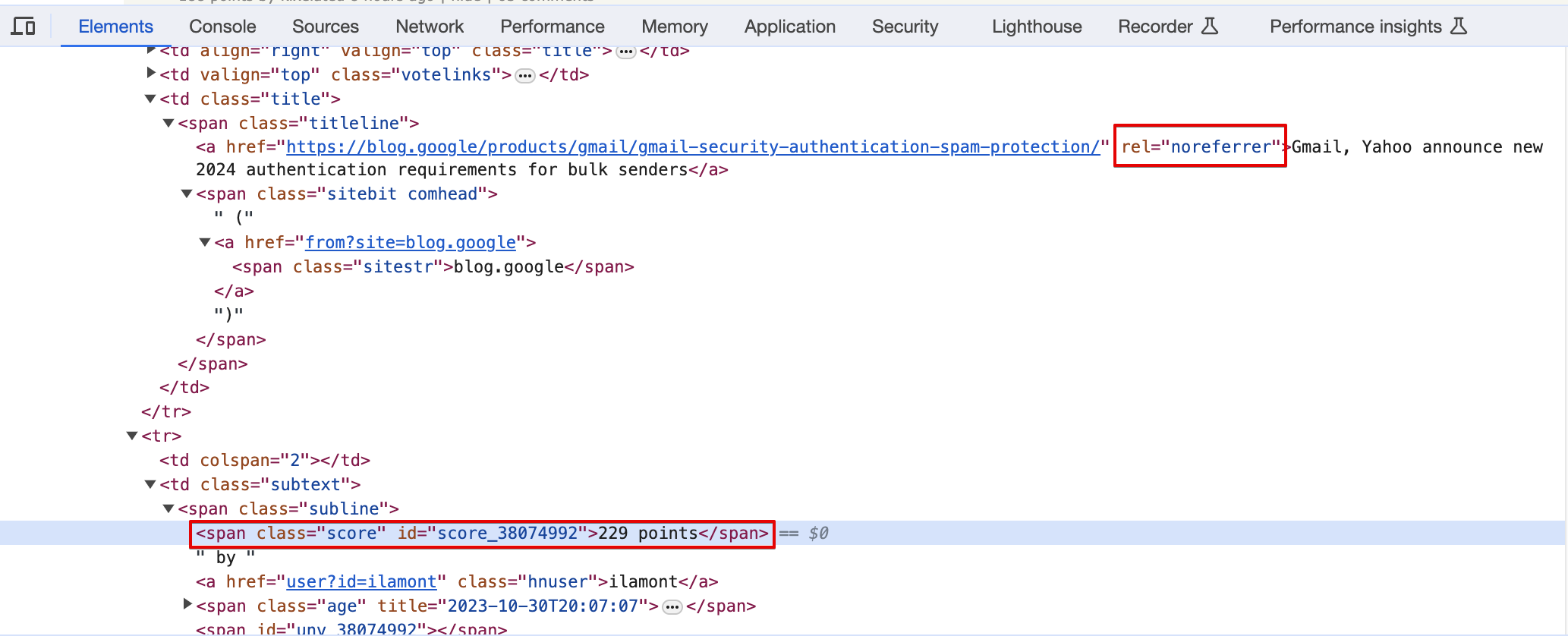
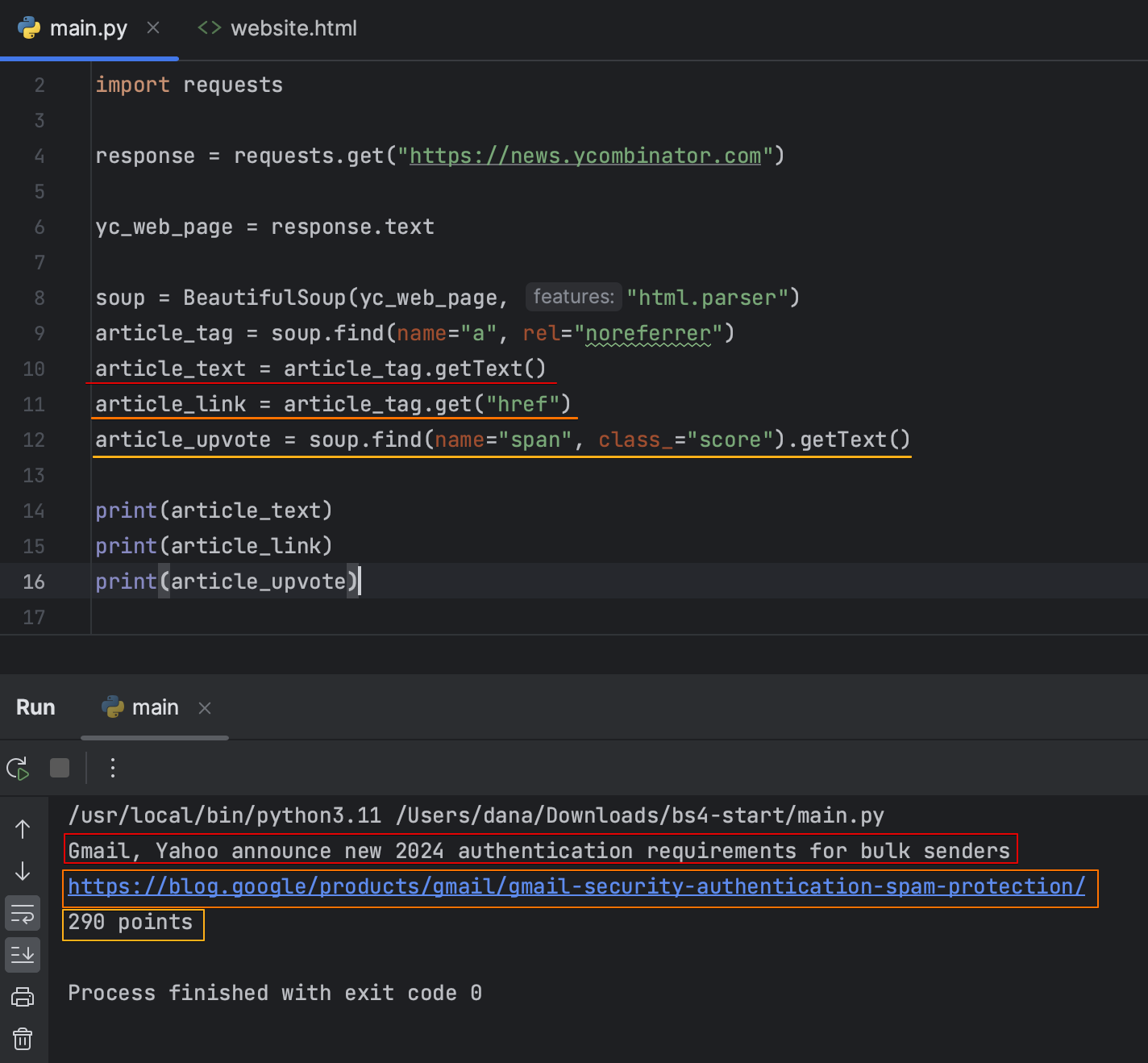
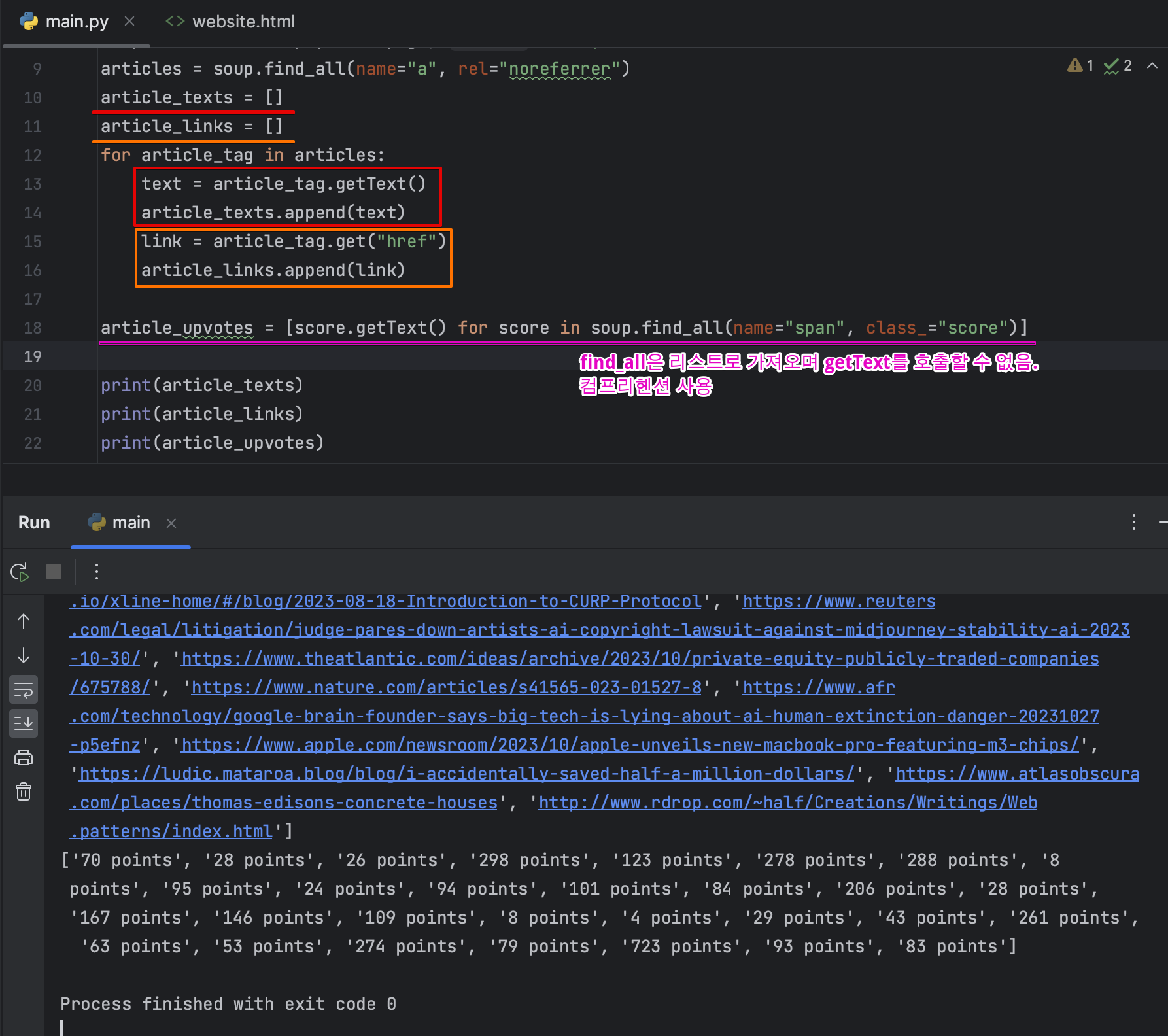
- 첫 항목이 아닌 페이지 모든 결과 가져오기
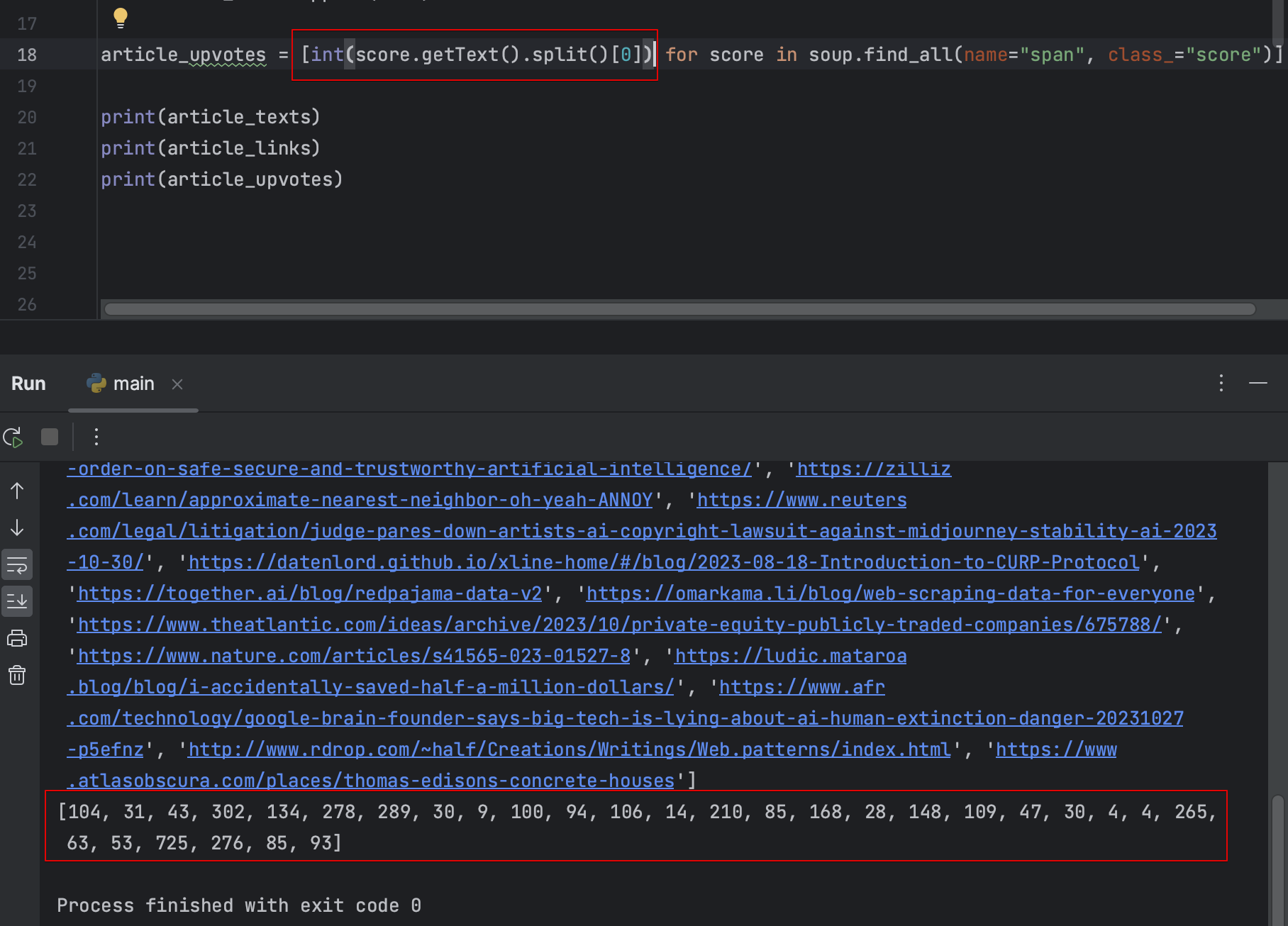
- 스코어 points제거, 숫자 정수화
-
가장 높은 값을 가진 인덱스 가져오기
-
인덱스를 통해 제목, 링크 가져오기
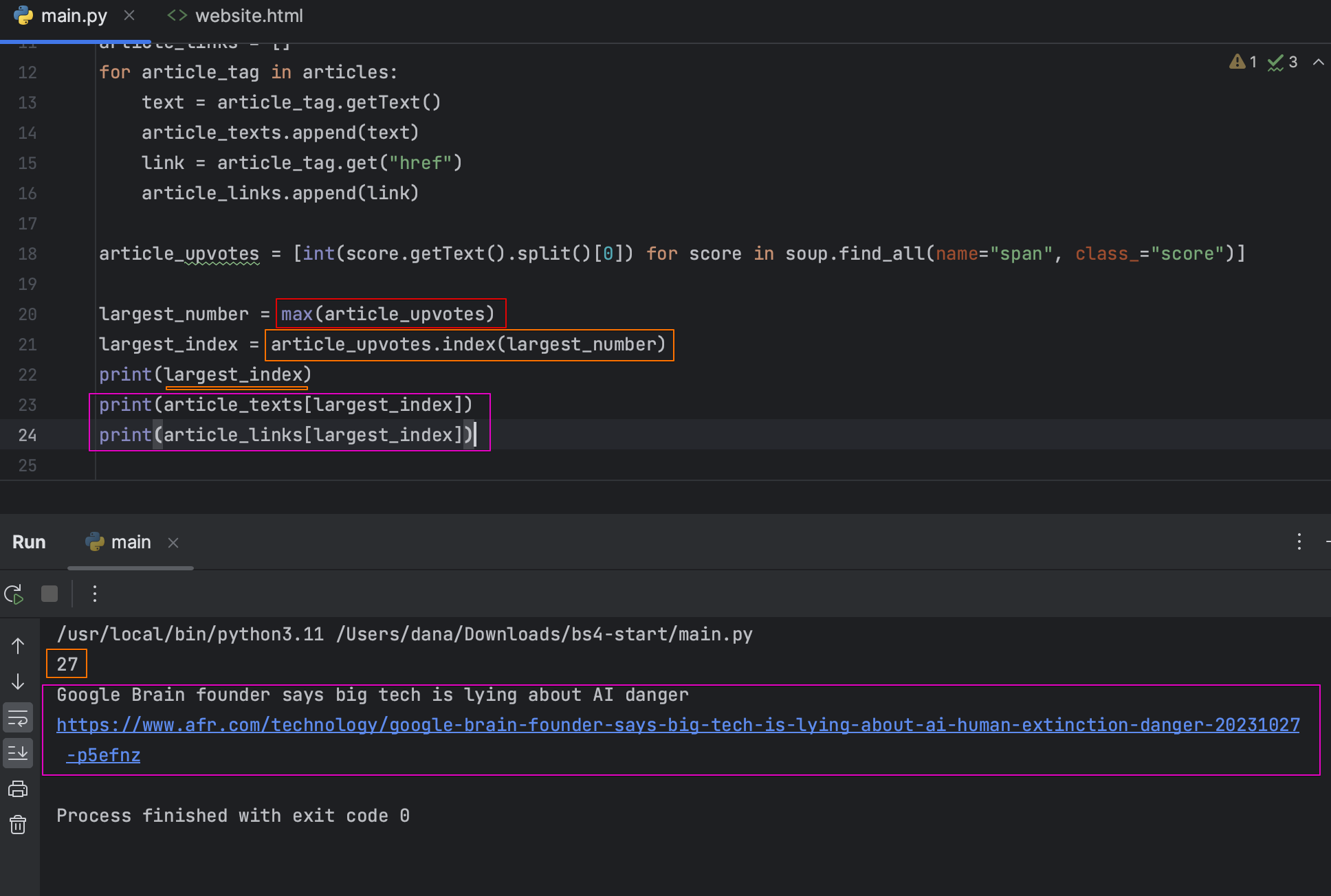
웹 스크랩핑은 합법인가?
- 웹사이트의 데이터가 공개되어 있고 로그인 없이 접근할 수 있으며 콘텐츠에 저작권이 존재하지 않는 경우 합법적으로 이용할 수 있다.
- 봇을 통해 웹스크랩핑을 방지하려고 많은 사이트들이 CAPTCHA를 활용
- 공공API가 있는 경우 항상 API를 사용해라
- com이나 co.kr같은 URL뒤에 /robots.txt를 입력하면 웹사이트를 스크랩하는 봇에게 제공하는 조언을 확인할 수 있음
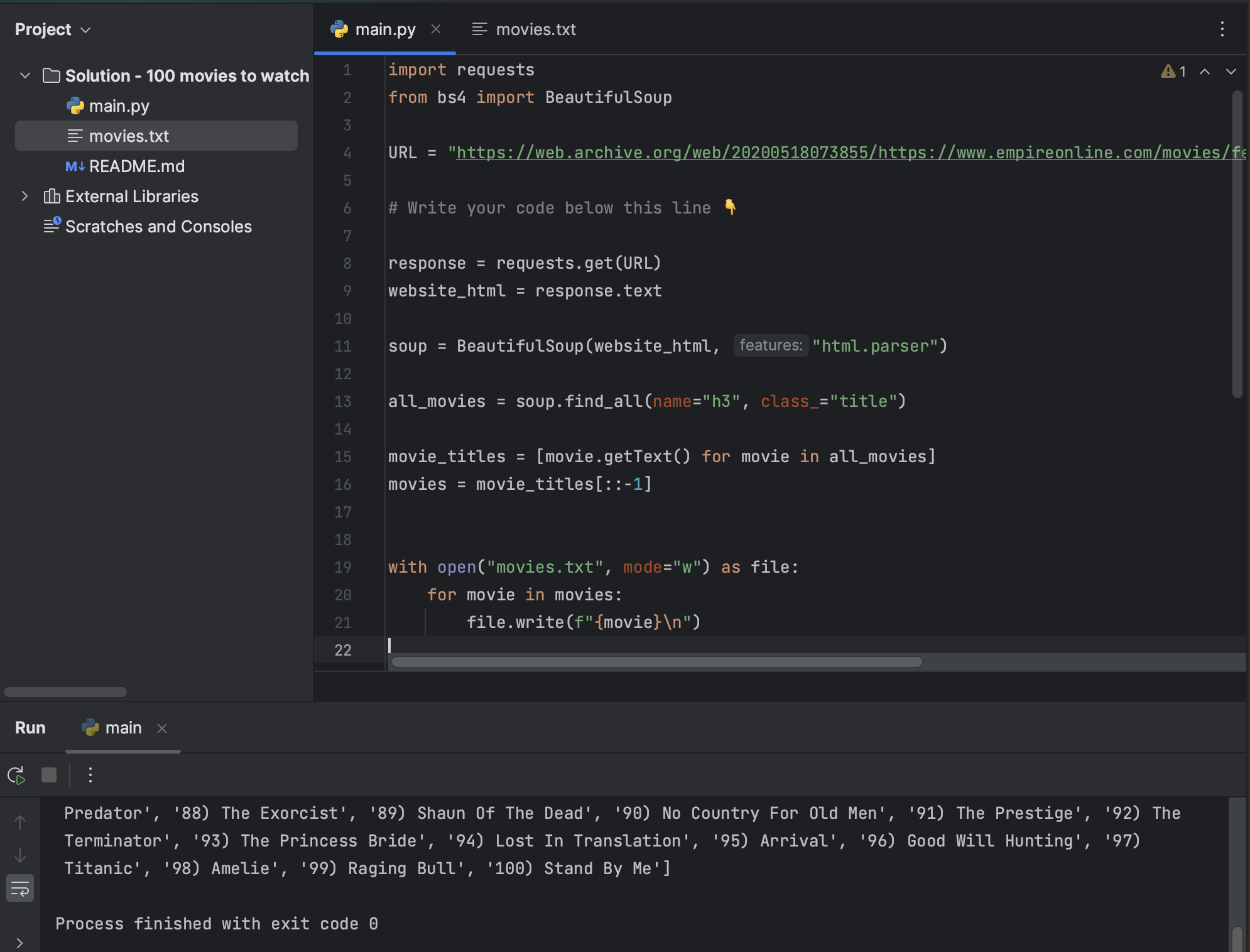
The 100 Greatest Movies
- URL복사
- 필요한 항목 import
- 타이틀 가져오기
- 컴프리헨션으로 텍스트만 얻기
- 리스트 순서 뒤집기 ⇨ splice 연산자를 사용 [: : -1]
- txt파일에 저장